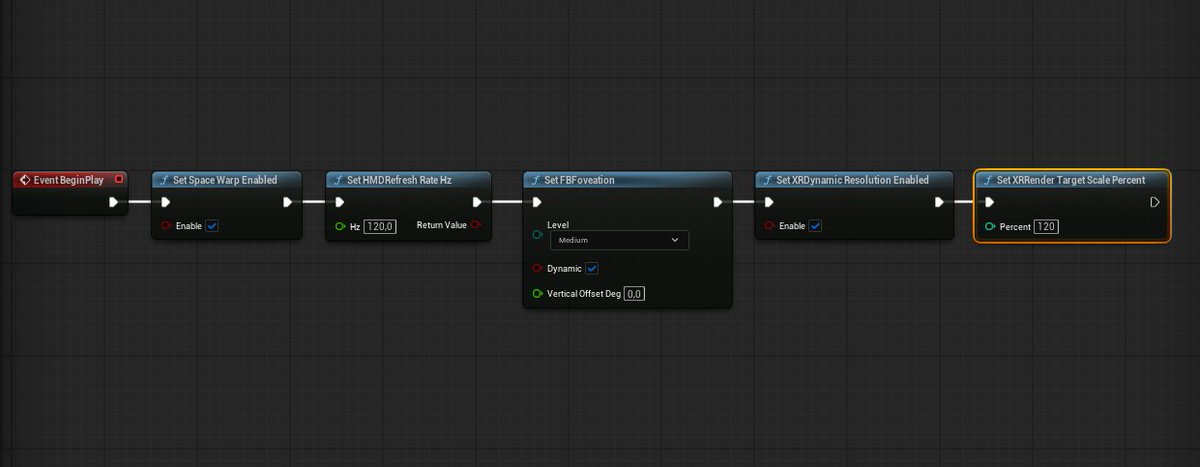
@footballontnt Sort out your commentary audio it’s clearly feeding back mic monitor into main mic and echoing. Unwatchable
English
Rich Hemming
5.2K posts

@S_A_R_Lab
Research Fellow in Immersive Technology | Faculty @SociodigFutures @BristolUni | PhD @RHElecEng | Founder @S_A_R_Lab | #SpatialAudio #Realtime #XR #Inclusion


Building in realtime voice? See the difference in action 👇🏻

Every once in a while I meet someone who comes out of nowhere to bring a real breakthrough. @blevlabs is the latest that I've found. His AI is way more advanced than any I've seen that are publicly available. This is the first of two parts. Here you get to meet him. Will get the second video up tomorrow where he shows me his technology. Yes, they are long, but worthy of your viewing to see a very different thinker and where he came from before you see a little more of his technology.