Sabitlenmiş Tweet

Herbert B Schiller
2.7K posts
@SchillerLab
Director, Research Unit for Precision Regenerative Medicine @HelmholtzMunich; Professor @LMU_Muenchen




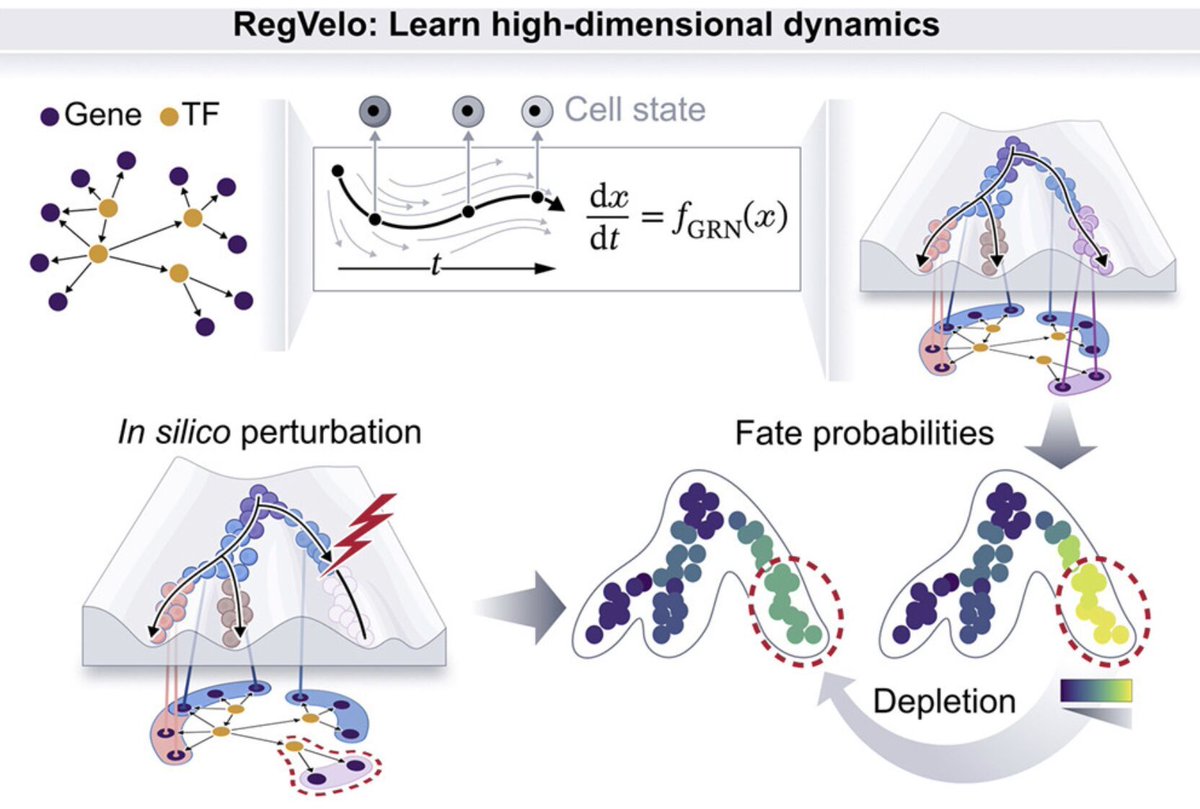







In AI-guided discovery, models often turn huge candidate pools into shortlists for costly validation. We ask: can we put an error budget on AI-generated shortlists before running the experiment? For example: • Can we keep failed hits below 10%? • How many candidates should we test to get enough true positives? • How far down the list can we go before expecting too many false positives? • If we already have a fixed top-K list, how many are likely wrong? 📢 Excited to share TxConformal, a framework to turn AI scores into shortlists with controlled/estimated false positives, even in tasks where new candidates differ from past experimental data. This is joint work with amazing @KexinHuang5 @jure @EmmanuelCandes , in collaboration with Genentech @nate_diamant @gabo_scalia. We test it across proteins, genetic perturbations, regulatory DNA, clinical trials, ADMET, and antibacterial virtual screening. In a prospective A. baumannii screen at Genentech, TxConformal estimated 80.3 false positives before wet-lab validation; the experiment found 91, within the 90% CI. Preprint: biorxiv.org/content/10.648… Code: github.com/ying531/TxConf… 🧵[1/n] 👇



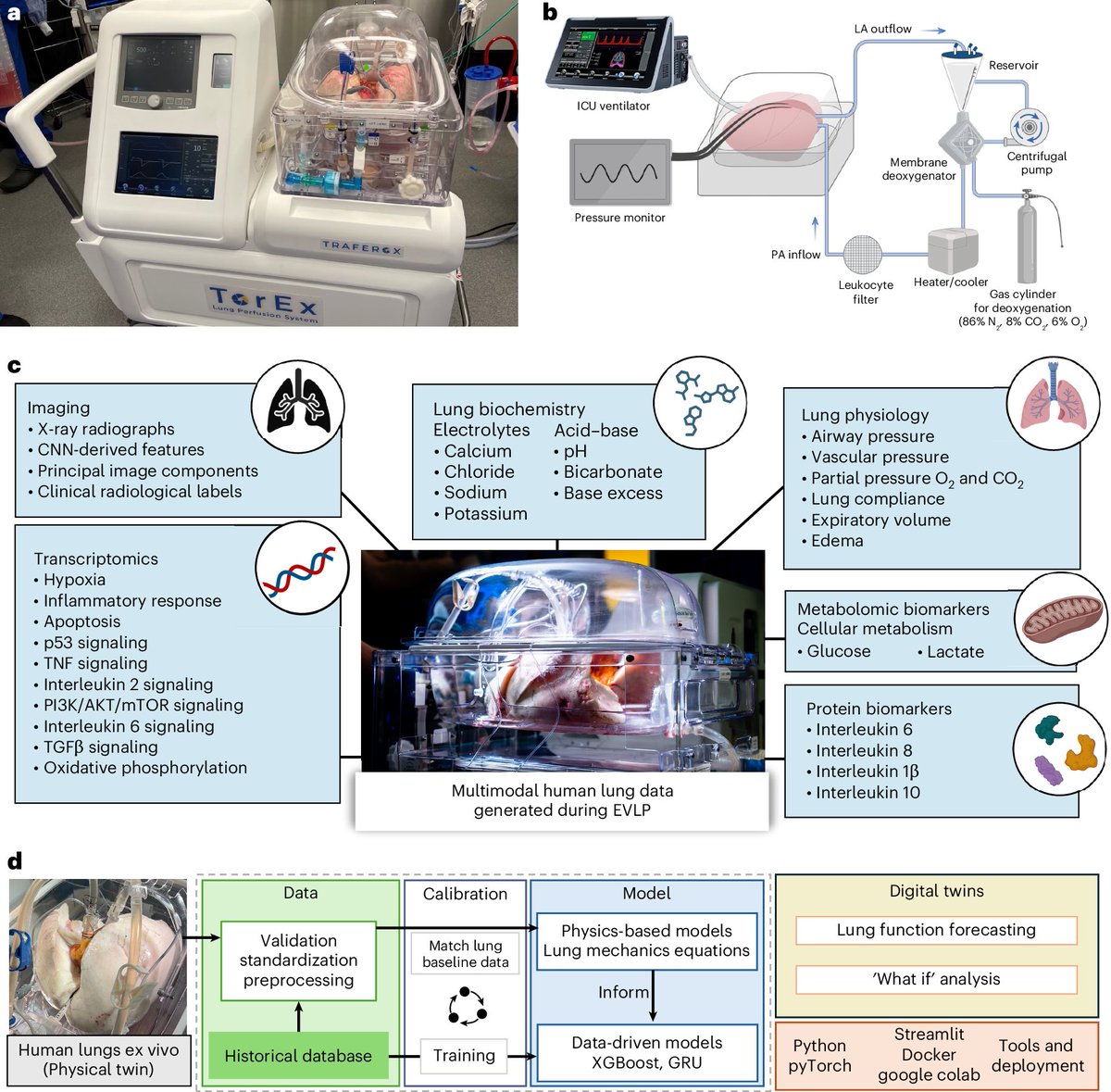









A weekly jab in the belly is generating more revenue than the entire AI industry. Ozempic + Mounjaro: $71B in 2025. OpenAI + Anthropic: $29B. And they've barely started. ~2% of the 800 million eligible patients can currently access them. h/t @DrSamuelBHume