
Sebastian BO
3K posts

Sebastian BO
@SebastianBO91
@HorseCareApp @VRParty1 @DogCare @PortfolioCare
Katılım Nisan 2014
3.3K Takip Edilen295 Takipçiler

Working dinner with Margaux Dietz @guxen
Hard working mom of 2 kids who wants Sweden to be a great place to live and build in

Fredrik Hjelm@FredrikHjelm4
Working lunch with @MartinLorentzon and @TheWesterFront. Happy International Workers’ Day.
English

I had the exact same question.
I see how AI can displace UIs (the human interface to software).
But APIs are the "programmatic" interface to software, so not sure how the AIs would replace that. Unless we're suggesting that whatever systems were calling APIs would call AI-based systems instead?
For some use-cases, I can see that (where AI is needed and non-determinism is acceptable).
But for a vast majority of APIs, doesn't seem like that's what's going to happen. APIs become unnecessary if the software they're providing access to becomes unnecessary, but I don't think they get replaced with AI.
English


@LemonSqueeze09 @Dimillian care to describe the bullshit and the depth?
English

A game I'm likely to push forward and open source. An ASCII Diablo lite, built entirely by Codex in Rust. I've told Codex to implement a preview system so it can run preview any UI or game state so it and debug/fix it.
English

@Oleg_shlyakhter @adcock_brett They are completely sim for their system 0 controller which controls walking, stairs, body movements etc. They have publicly stated that walking and stairs were both 0 shots
English

F.03 can now walk up/down stairs purely using it's onboard camera perception
Our robots now walk from manufacturing when built to HQ
This is trained end-to-end with reinforcement learning in simulation
English
@OpenRouter Brilliant, and it continues to be built? After 1 year it should cover quite a lot?
English

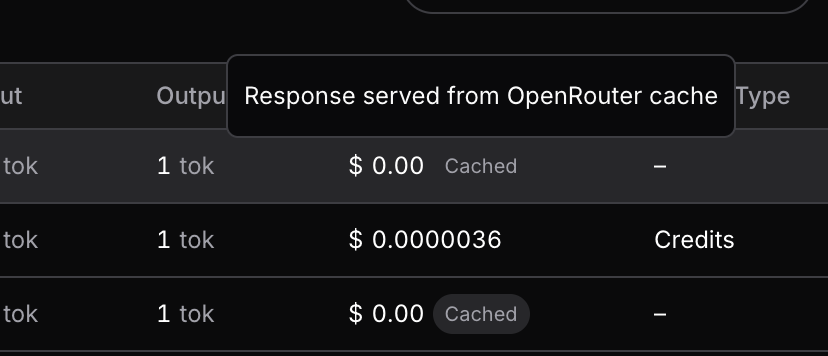
Introducing Response Caching: save tons of money and time on tests and agent retries.
Blog post: openrouter.ai/announcements/…
Available for free. Learn more 👇
English
English

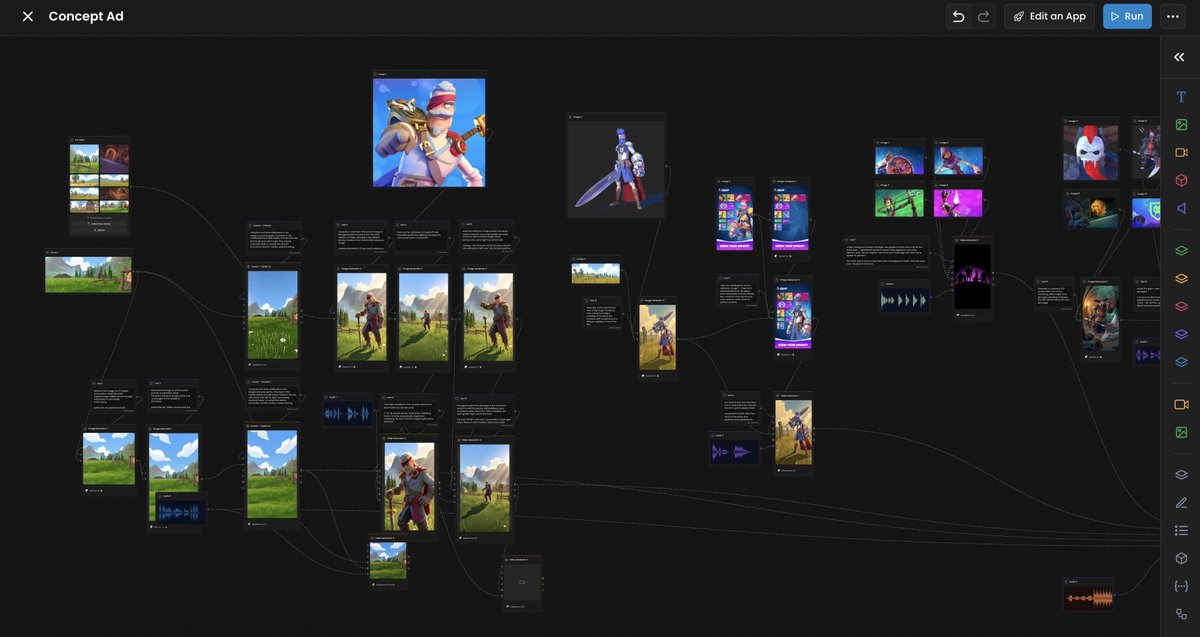
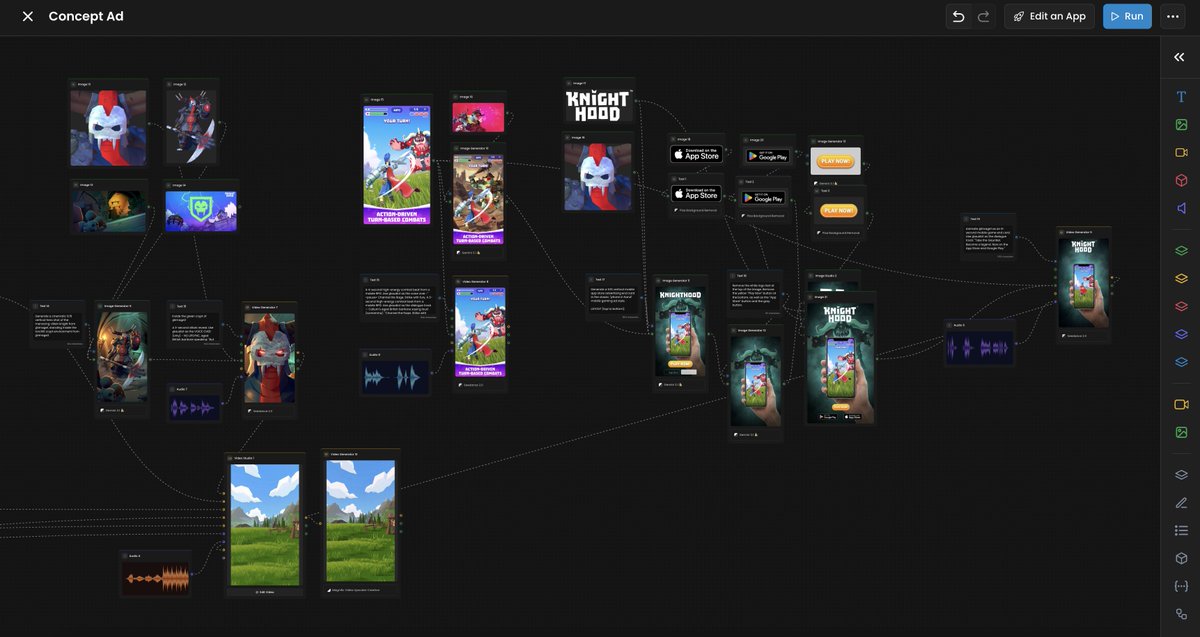
That was one seriously heavy workflow, made for a 35-second concept ad.
The final output was built 100% in @Scenario_gg + @cursor_ai (Scenario MCP). No video editing software involved.
80+ nodes, multiple models, including:
- Gemini 3.1 (images)
- Seedance 2.0 (video)
- ElevenLabs (TTS + Music Advanced)
- Magnific (video upscaling)
- Photoroom (background removal)
- some utility nodes stitching everything together.
English

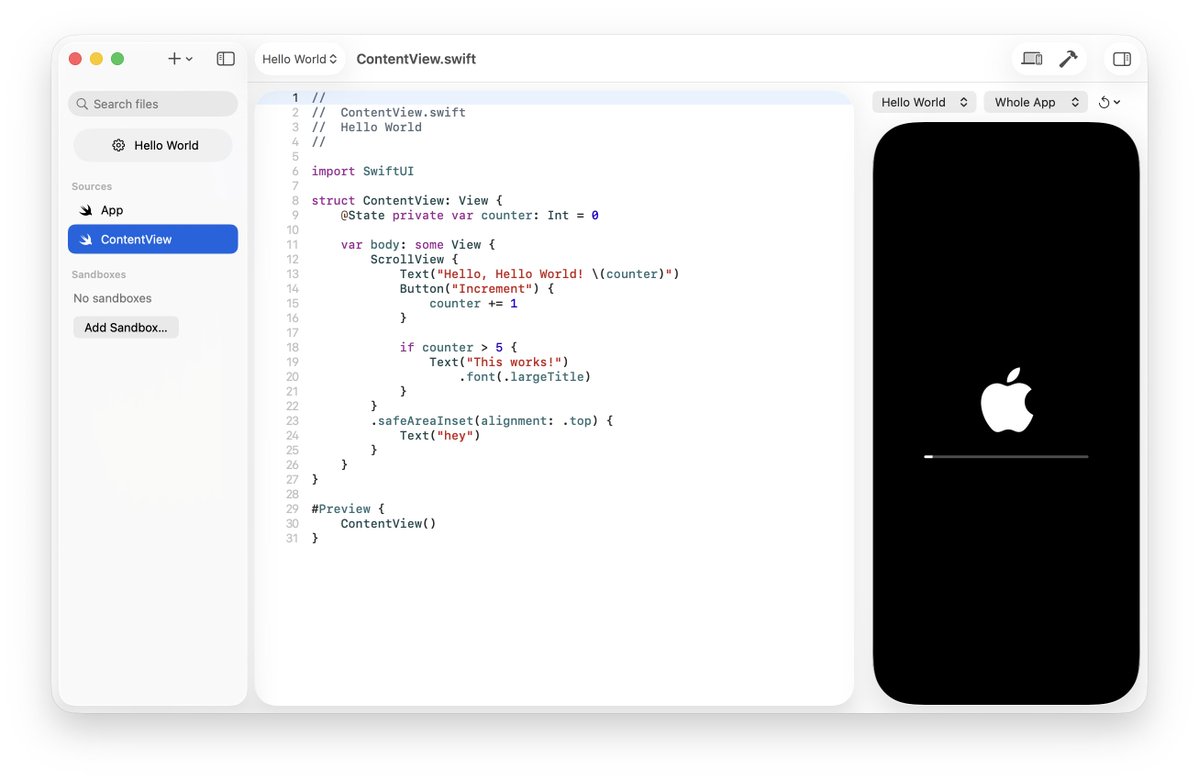

Claude can even do SVG animations now.. nah ok we might be cooked fr man..
Claude@claudeai
Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude. Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
English
@varun_mathur Super!! Good idea to even make it possible to connect mobile devices?
English

Introducing Pods
Hyperspace Pods lets a small group of people - a family, a startup, a few friends, to pool their laptops and desktops into one AI cluster. Everyone installs the CLI, someone creates a pod, shares an invite link, and the machines form a mesh. Models like Qwen 3.5 32B or GLM-5 Turbo that need more memory than any single laptop has get automatically sharded across the group's devices - layers split proportionally, inference pipelined through the ring. From the outside it looks like one OpenAI-compatible API endpoint with a pk_* key that drops straight into your AI tools and products. No configuration beyond pasting the key and changing the base URL.
A team of five paying for cloud AI burns $500–2,000 a month on API calls. The same team's existing machines can serve Qwen 3.5 (competitive on SWE-bench) and GLM-5 Turbo (#1 on BrowseComp for tool-calling and web research) for free - the hardware is already on their desks. When a query genuinely needs a frontier model nobody has locally, the pod falls back to cloud at wholesale rates from a shared treasury. But for the daily work - code reviews, refactors, research, drafting - local models handle it and nobody gets billed. And when it is idle, you can rent out your pod on the compute marketplace, with fine-grained permissions for access management.
There's no central server involved in inference. Prompts go from your machine to your pod members' machines and back: all of this enabled by the fully peer-to-peer Hyperspace network. Pod state - who's a member, which API keys are valid, how much treasury is left - is replicated across members with consensus, so the whole thing works on a local network. Members behind home routers don't need port forwarding either. The practical setup for most pods is three models covering different jobs: Qwen 3.5 32B for code and reasoning, GLM-5 Turbo for browsing and research, Gemma 4 for fast lightweight tasks. All running on hardware you already own.
Pods ship today in Hyperspace v5.19. Model sharding, API keys, treasury, and Raft coordinator are all live.
What Makes This Different - No middleman. Your prompts travel from your IDE to your pod members' hardware and back. There is no server in between reading your data.
- No vendor lock-in. Pod membership, API keys, and treasury are replicated across your own machines using Raft consensus. If the internet goes down, your local network keeps working. There is no database in someone else's cloud that your pod depends on.
- Automatic sharding. You don't configure layer ranges or calculate VRAM budgets. Tell the pod which model you want. It figures out how to split it across whatever hardware is online.
- Real NAT traversal. Your friend behind a home router with a dynamic IP? Works. No VPN, no Tailscale, no port forwarding. The nodes handle it.
- Free when local. This is the part that matters most. Cloud AI bills scale with usage. Pod inference on local hardware scales with nothing. The marginal cost of your 10,000th prompt is the electricity your laptop was already using.
Coming soon:
- Pod federation: pods form alliances with other pods.
- Marketplace: pods with spare capacity can sell inference to other pods.
English

DDTree paired with DFlash cuts inference time by another ~40%. So ~40% saving with DFlash and then another ~40% on top!
Liran Ringel@liranringel
Introducing DDTree: accelerates speculative decoding by drafting a tree with one block diffusion pass, then verifying multiple likely continuations together. Paper: liranringel.github.io/ddtree/DDTree.… Project page: liranringel.github.io/ddtree Code: github.com/liranringel/dd…
English

Genie3 generates videos. We generate 𝟯𝗗 𝘄𝗼𝗿𝗹𝗱𝘀 you can actually use.
Launching tomorrow — Tencent #HYWorld 2.0, an engine-ready World Model🚀
This isn't a video. It's a real 3D scene, all generated & editable. One image in. A whole 3D world out.
🔥Open-source tomorrow
English
@gajesh YEEEES!! Brilliant, super stoked about this. Great Initiative 😃🫡
English

Wake the world's sleeping compute.
Look at the Mac nearest to you. What's it doing?
Probably nothing.
There are 100M+ Macs with Apple Silicon out there. Apple quietly made them *really* good at inference. A $3k Mac runs a 60B model at 30 watts.
Most sit idle most of the day.
Meanwhile every AI API call passes through three layers of margin before reaching the hardware. We call this the Inference Tax.
We got curious: what happens if you connect idle Macs directly to inference demand?
This is Darkbloom. Private inference network for idle Macs.
darkbloom [dot] dev -- paper + code open.
Reply for invite + free credits ↓
English

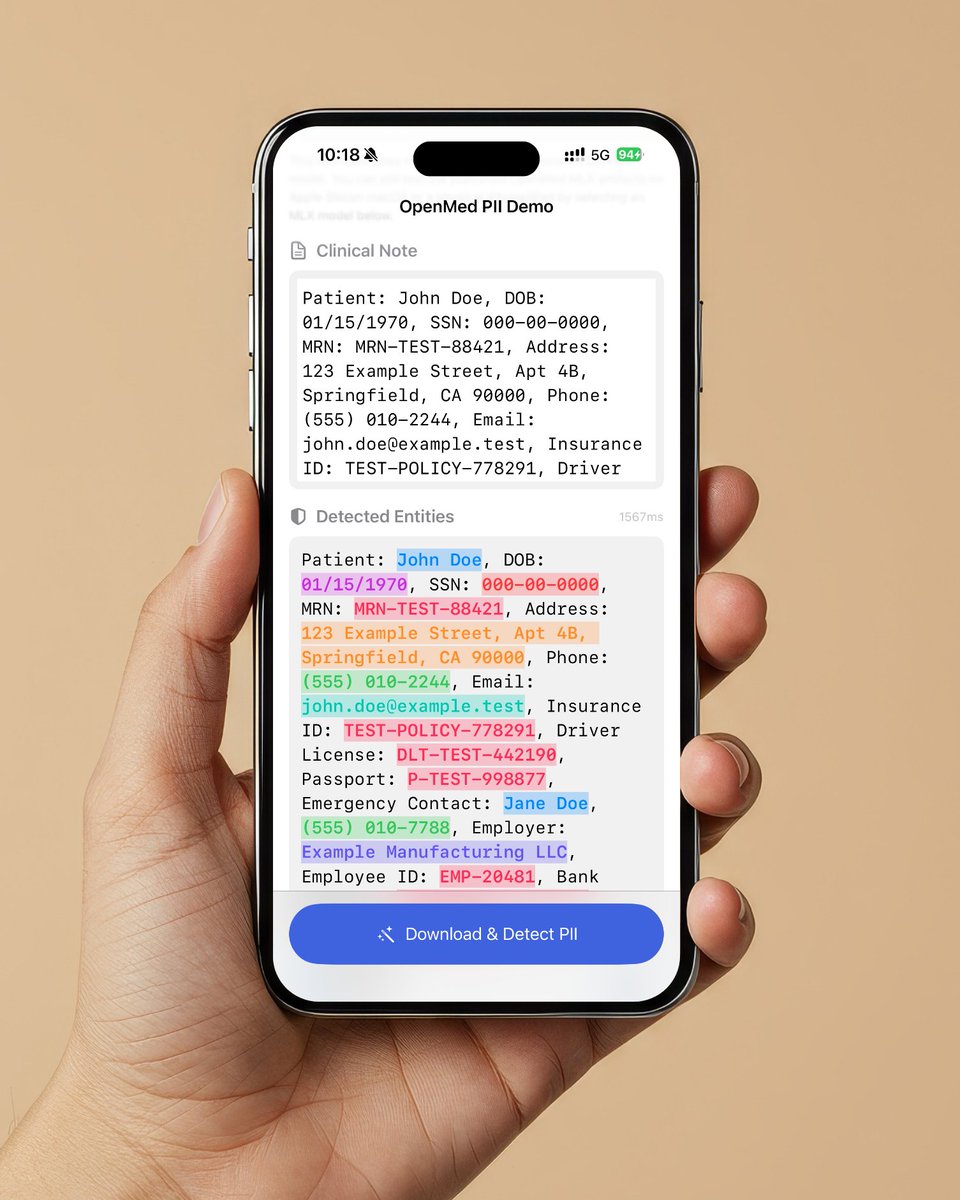
Medical AI models now run on iPhone. No cloud. No API.
OpenMed 1.0.0 just shipped.
MLX backend for Apple Silicon. Swift package for macOS and iOS. 200+ PII detection models across 8 languages.
pip install openmed
Open source. Apache 2.0.
English
Sebastian BO retweetledi

Hermes Agent v0.9.0 - “The Everywhere Release”
Full changelog below ↓
English

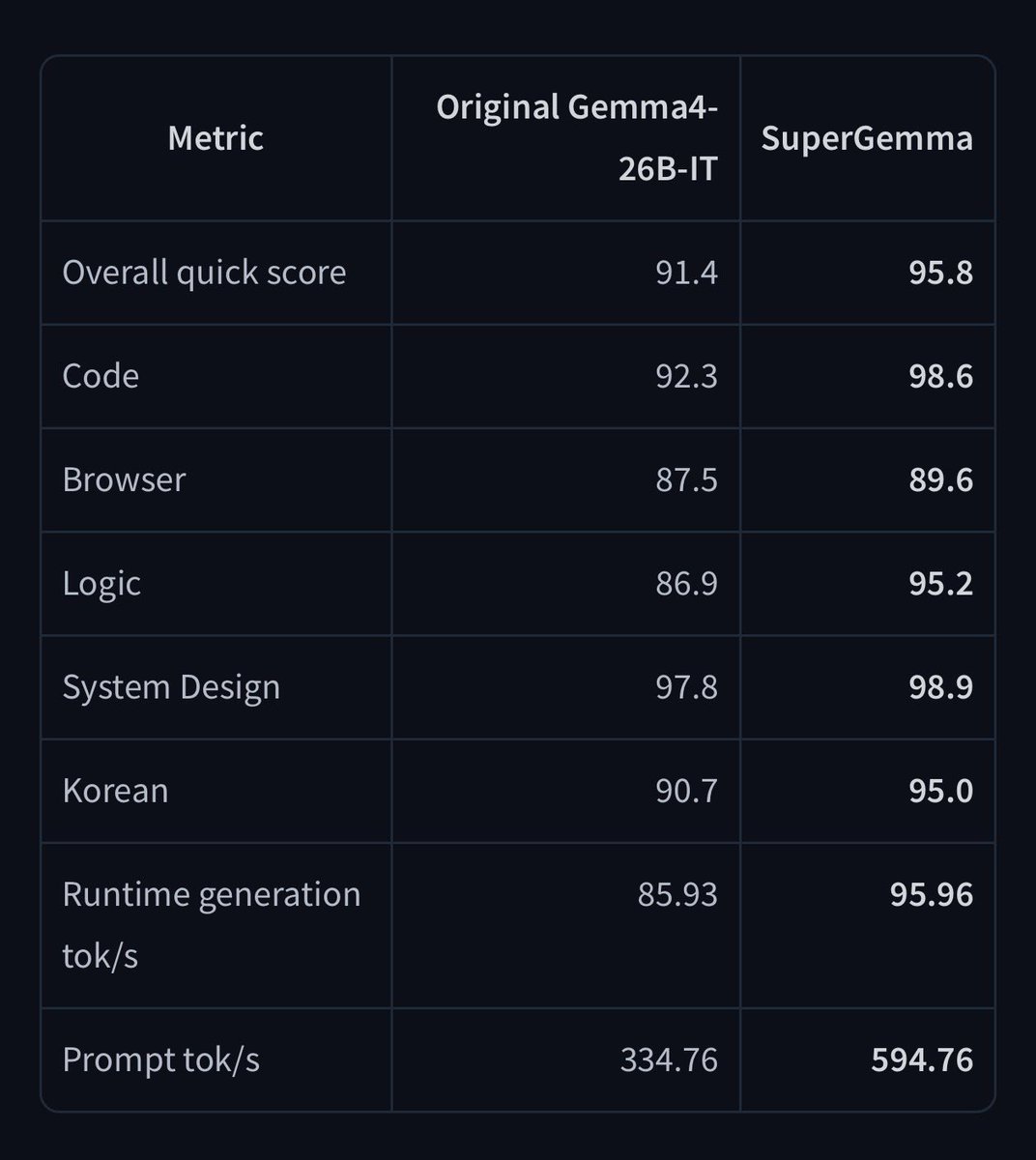
gemma4-26b의 완벽한 파인튜닝을 성공했습니다.
- 0/100 refusal 완벽 무검열
- 툴콜/토크나이저 모델 태생 이슈 해결
- 벤치기준 기존 대비 성능 10% 향상
- 출력토큰 속도 10% 향상
- 프롬프트 처리속도 약 90% 향상
완벽한 모델이 완성되었다고 생각합니다.
gguf / mlx 두개 버전 ⬇️
한국어
Sebastian BO retweetledi

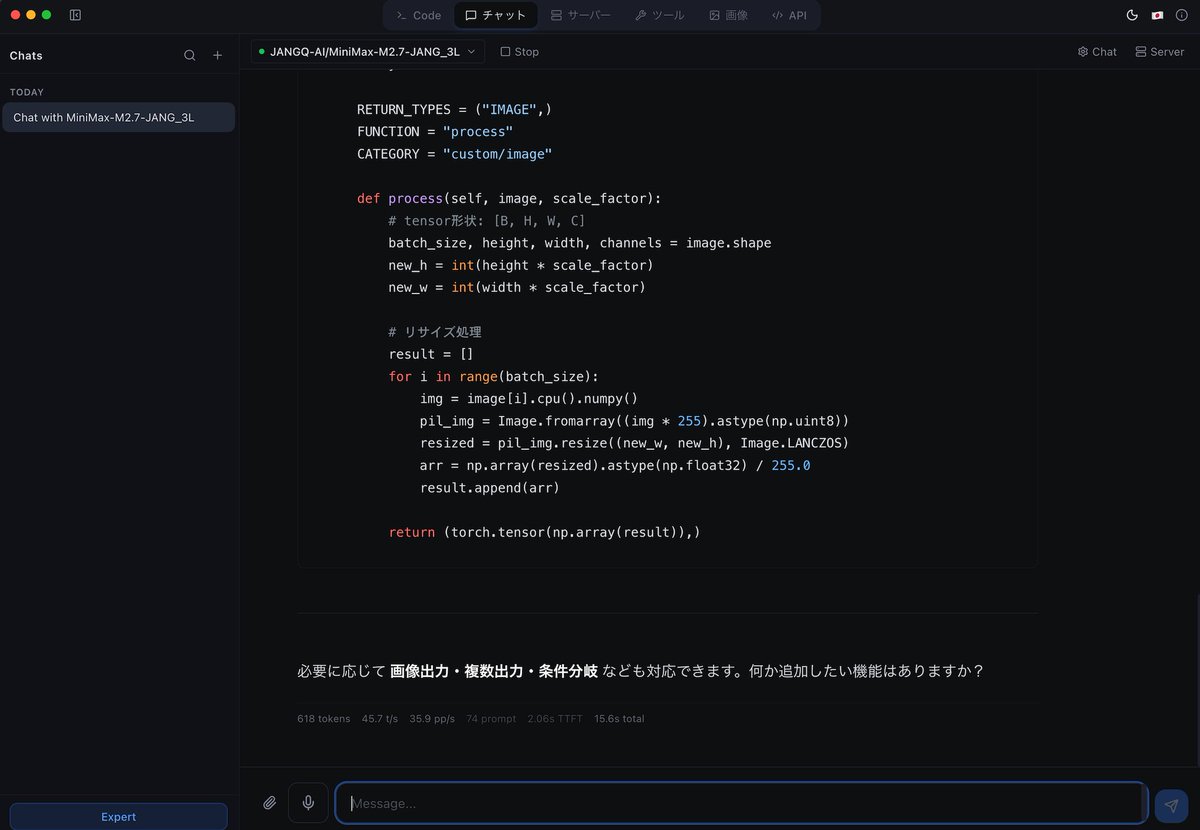
最近どうもLM StudioのMLX対応がイマイチなので、MLX Studioを入れてみた。最近流行りのいろいろなcache形式に対応してるし速度も速い!< JANGQ-AI/MiniMax-M2.7-JANG_3Lで45.7 t/s35.9 pp/s。 Macな人はお試しを
mlx.studio
日本語



Sebastian BO retweetledi

mesh-llm: pool compute to run open models. built by @michaelneale at block: docs.anarchai.org
English
Sebastian BO retweetledi

Seedance 2.0 is impressive. But it's closed-source!
Introducing our daVinci-MagiHuman — a single-stream 15B Transformer trained from scratch that jointly generates video + audio. No cross-attention. No multi-stream branches. Just self-attention.
⚡ 5s 1080p video in 38s on a single H100
🏆 80% win rate vs Ovi 1.1 | 60.9% vs LTX 2.3 (2,000 human comparisons)
🌍 6 languages
📦 Fully open-source
Speed by simplicity.
By @SII_GAIR × @SandAI_HQ
📄 arxiv.org/abs/2603.21986
💻 github.com/GAIR-NLP/daVin…
🤗 huggingface.co/spaces/SII-GAI…
English