Sabitlenmiş Tweet
3ali
1.7K posts


3ali
@alielfilali01
Dedicated to AI and Atay 🫖🥃 | Evals @G42ai | Building better evals @evaluatingevals
🇲🇦 Katılım Haziran 2020
1.8K Takip Edilen215 Takipçiler
3ali retweetledi

Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference”
We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to prompt engineering. Here we share what we are working on and connect with the research community frequently and openly.
The name Connectionism is a throwback to an earlier era of AI; it was the name of the subfield in the 1980s that studied neural networks and their similarity to biological brains.
thinkingmachines.ai/blog/defeating…

English
3ali retweetledi

A big part of our mission at Thinking Machines is to improve people’s scientific understanding of AI and work with the broader research community. Introducing Connectionism today to share some of our scientific insights.
Thinking Machines@thinkymachines
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to prompt engineering. Here we share what we are working on and connect with the research community frequently and openly. The name Connectionism is a throwback to an earlier era of AI; it was the name of the subfield in the 1980s that studied neural networks and their similarity to biological brains. thinkingmachines.ai/blog/defeating…
English
3ali retweetledi

Fei-Fei Li (@drfeifei) on limitations of LLMs.
"There's no language out there in nature. You don't go out in nature and there's words written in the sky for you.. There is a 3D world that follows laws of physics."
Language is purely generated signal.
English
3ali retweetledi

@francoisfleuret Scaling up old ideas, with 10x the compute and a fancy acronym
English
3ali retweetledi

We were able to reproduce the strong findings of the HRM paper on ARC-AGI-1.
Further, we ran a series of ablation experiments to get to the bottom of what's behind it.
Key findings:
1. The HRM model architecture itself (the centerpiece of the paper) is not an important factor.
2. The outer refinement loop (barely mentioned in the paper) is the main driver of performance.
3. Cross-task transfer learning is not very helpful. What matters is training on the tasks you will test on.
4. You can use much fewer data augmentations, especially at inference time.
Finding 2 & 3 mean that this approach is a case of *zero-pretraining test-time training*, similar to the recently published "ARC-AGI without pretraining" paper by Liao et al.
English
3ali retweetledi

One perk of working on @AtlasIA projects: we get to confirm big-lab findings with limited community budget💪
We finetuned Qwen2.5-VL at two scales to find the sweet spot for LR × batch size and saw patterns validating DeepSeek’s scaling laws 📈
(arxiv.org/pdf/2401.02954).

English
@AnassAb01 @Omar_H_ On a different note, i just don't understand why some people enjoy being as*holes!
You could've just shared the blody link man!
English
@AnassAb01 @Omar_H_ maybe this is the "report" you want: drive.google.com/file/d/1OdU0-C…
Indeed the information mentioned by detafour is WRONG ! Maybe they misunderstood the 21st slide (which is the exact opposite of what they mentioned)
Nevertheless, we are still not at the top of our game yet !!!
English

This is insane 6 months and no more than a 100K$ in Startup Funding.
I can't stop but think: "That's it, FORSA, 212 FOUNDERS, PLUG N PLAY, UM6P VENTURES... and that's it a 100K$"
But again, I went to an Agri-Tech Incubator Demo Day and I've seen people pitching "JAM" (confiture a3ibad lah) as a Start Up idea and those were the finalists.

English
@AnassAb01 @Omar_H_ Also, i guess it's worth to mention that generally most the funding we have is internal (local VCs), while south africa and egypt lead given the British and GCC VCs respectively.
Not justifying falling behind here, but maybe one of the reasons!
English
3ali retweetledi

🚨 New blog: The AI Evaluation Chart Crisis 📝
From misleading bar heights to missing error bars, recent model launches have sparked debate on AI evals. In our new blogpost, we dig into what’s broken, why it matters and how they should be presented 👇
evalevalai.com/documentation/…
English
We went from cherry picking benchmarks to cherry picking models...
Wondering why 4.1 opus *with* thinking is not there 👀
Elon Musk@elonmusk
Grok wins hands-down at coding. It wasn’t close.
English
3ali retweetledi

We have a long history of using games to measure progress in AI. 🎮
That’s why we’re helping unveil the @Kaggle Game Arena: an open-source platform where models go head-to-head in complex games to help us gauge their capabilities. 🧵
GIF
English
3ali retweetledi
🚨 AI Evals Crisis: Officially kicking off the Eval Science Workstream 🚨
We’re building a shared scientific foundation for evaluating AI systems, one that’s rigorous, open, and grounded in real-world & cross-disciplinary best practices👇 (1/2)
evalevalai.com/research/2025/…
English
3ali retweetledi


3ali retweetledi

ChemPile: A 250GB Diverse and Curated Dataset for Chemical Foundation Models
"We present the ChemPile, an open dataset containing over 75 billion tokens of curated chemical data, specifically built for training and evaluating general-purpose models in the chemical sciences."

English
3ali retweetledi

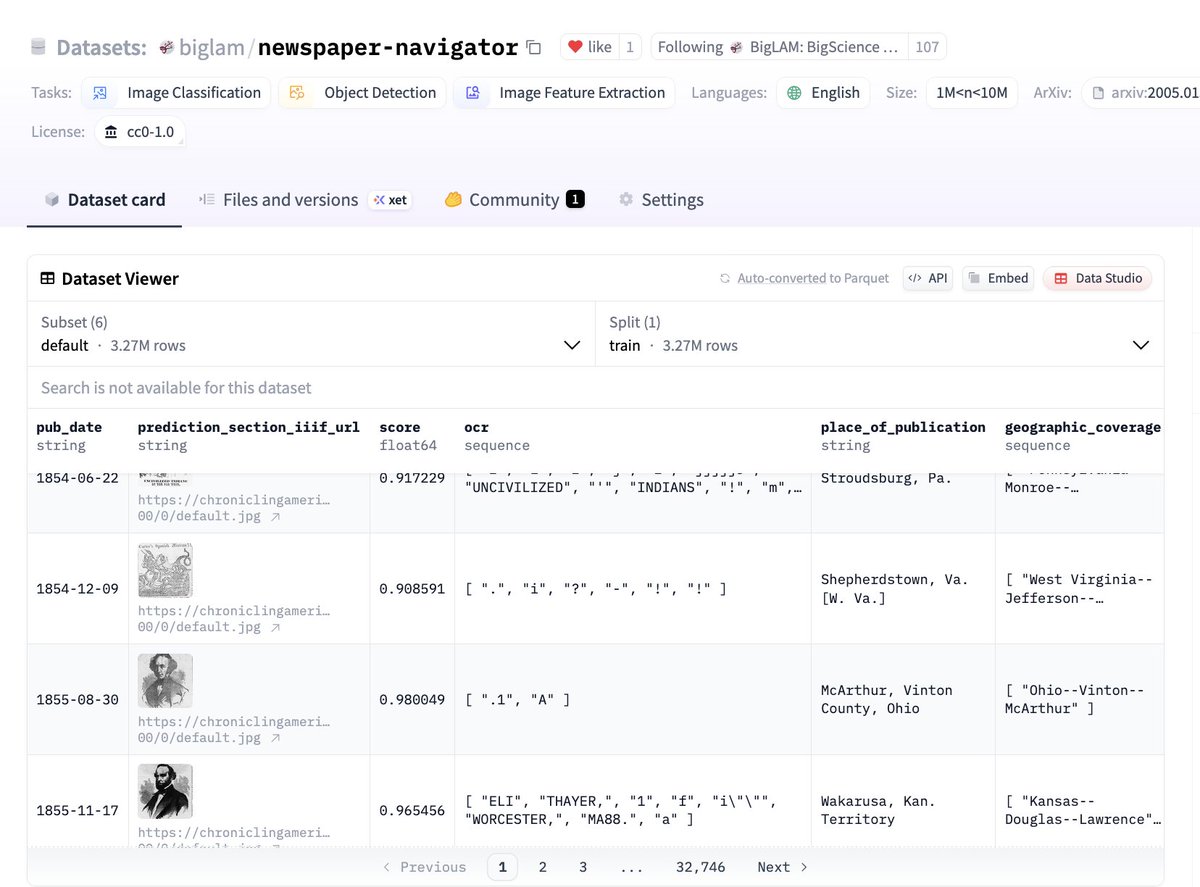
Just released: A Parquet-converted version of the Newspaper Navigator dataset on @huggingface!
📰3M+ visual annotations from historic US newspapers from @ChronAmLOC
🗂️ Bounding boxes, OCR, metadata + IIIF crop URLs
📸 Covers photos, cartoons, comics, maps & more
English
3ali retweetledi

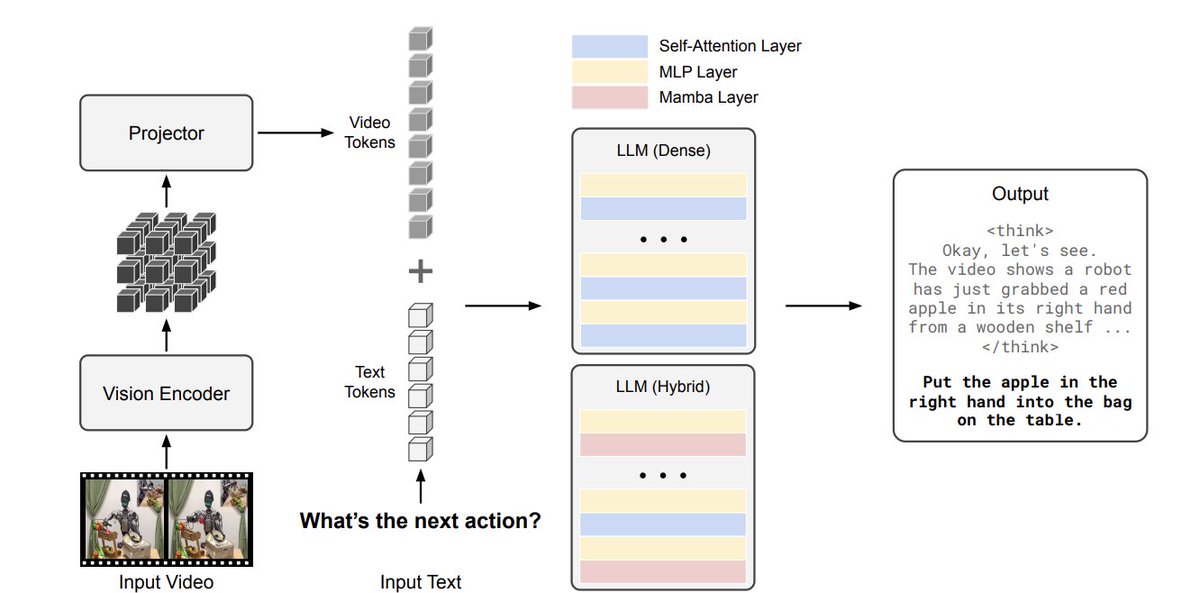
NVIDIA released new vision reasoning model for robotics: Cosmos-Reason1-7B 🤖
> first reasoning model for robotics 😱
> based on Qwen 2.5-VL-7B, use with @huggingface transformers or vLLM 🤗
> comes with SFT & alignment dataset and a new benchmark 👏
English
3ali retweetledi

I'm excited to share our new pre-print
ShiQ: Bringing back Bellman to LLMs!
arxiv.org/abs/2505.11081
In this work, we propose a new, Q-learning inspired RL algorithm for finetuning LLMs 🎉
(1/n)
English
3ali retweetledi

I reviewed "These Strange New Minds: How AI Learned to Talk and What It Means" by Chris Summerfield.
⬇️
English