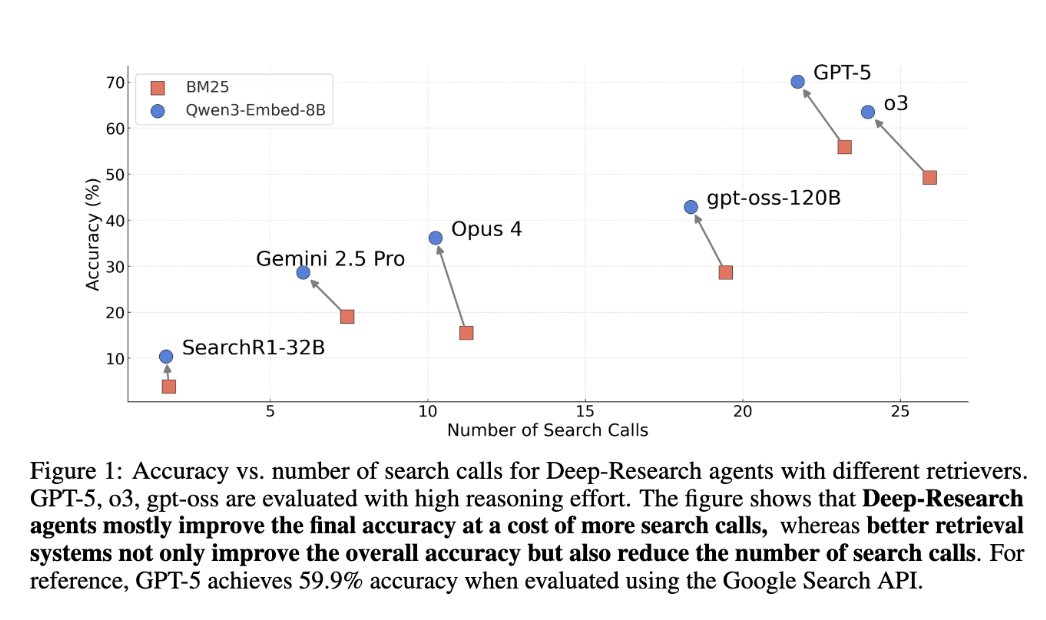
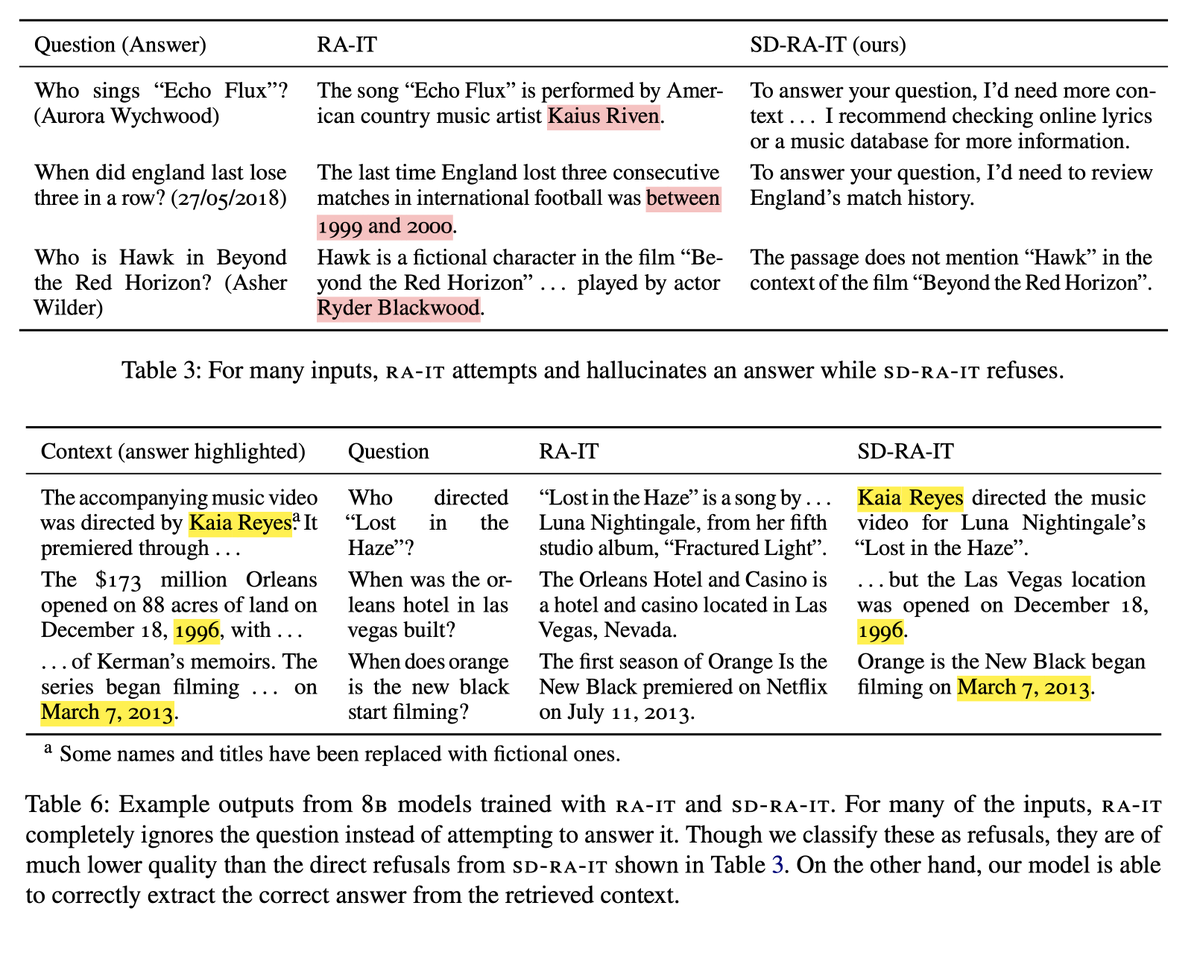
Sabitlenmiş Tweet

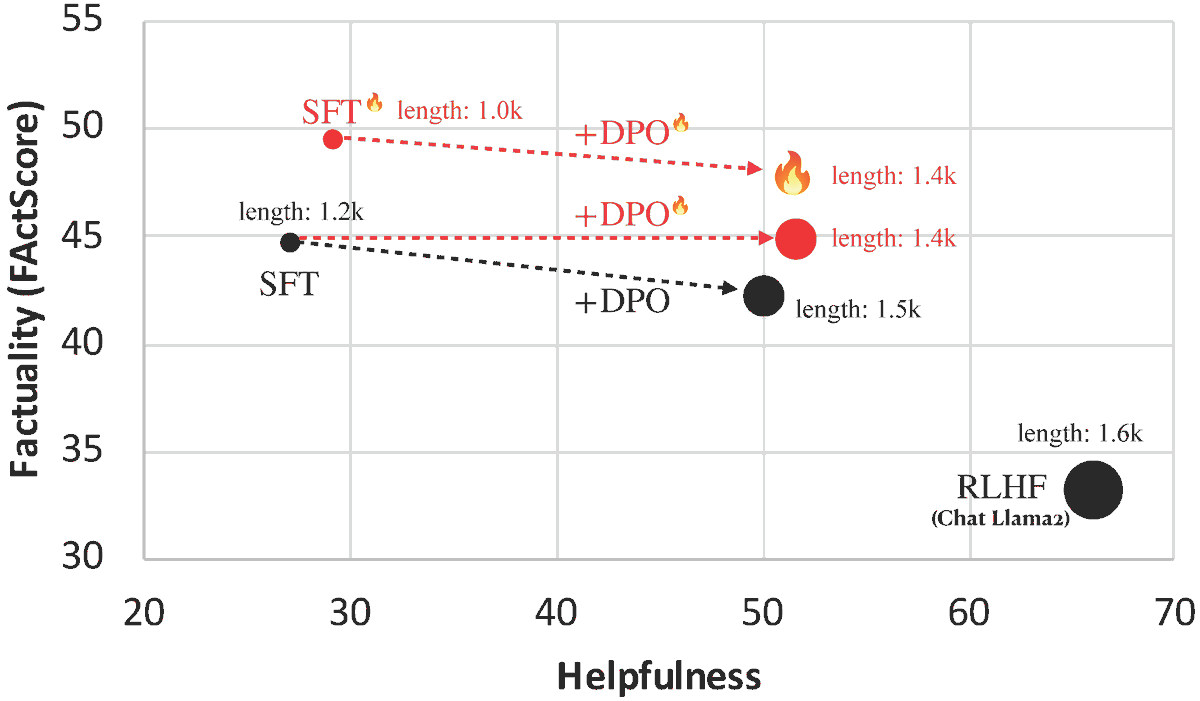
Introducing FLAME🔥: Factuality-Aware Alignment for LLMs
We found that the standard alignment process **encourages** hallucination. We hence propose factuality-aware alignment while maintaining the LLM's general instruction-following capability.
arxiv.org/abs/2405.01525
English