
idol2vec
385 posts

This is a cool article that shows how to *actually* make filesystems + grep replace a naive RAG implementation.
̶F̶i̶l̶e̶s̶y̶s̶t̶e̶m̶s̶ ̶+̶ ̶g̶r̶e̶p̶ ̶i̶s̶ ̶a̶l̶l̶ ̶y̶o̶u̶ ̶n̶e̶e̶d̶ ̶
Database + virtual filesystem abstraction + grep is all you need

Dens Sumesh@densumesh
Español

🚀 6 WAYS TO USE IT
HuggingFace Spaces — zero setup, runs on ZeroGPU, free daily quota with HF Pro
Local web UI — same Gradio interface on your own GPU
Google Colab — free T4, works up to ~8B params
CLI — one command: obliteratus obliterate model --method advanced
Python API — full programmatic control, every intermediate artifact exposed
YAML configs — reproducible studies you can version-control and share

English
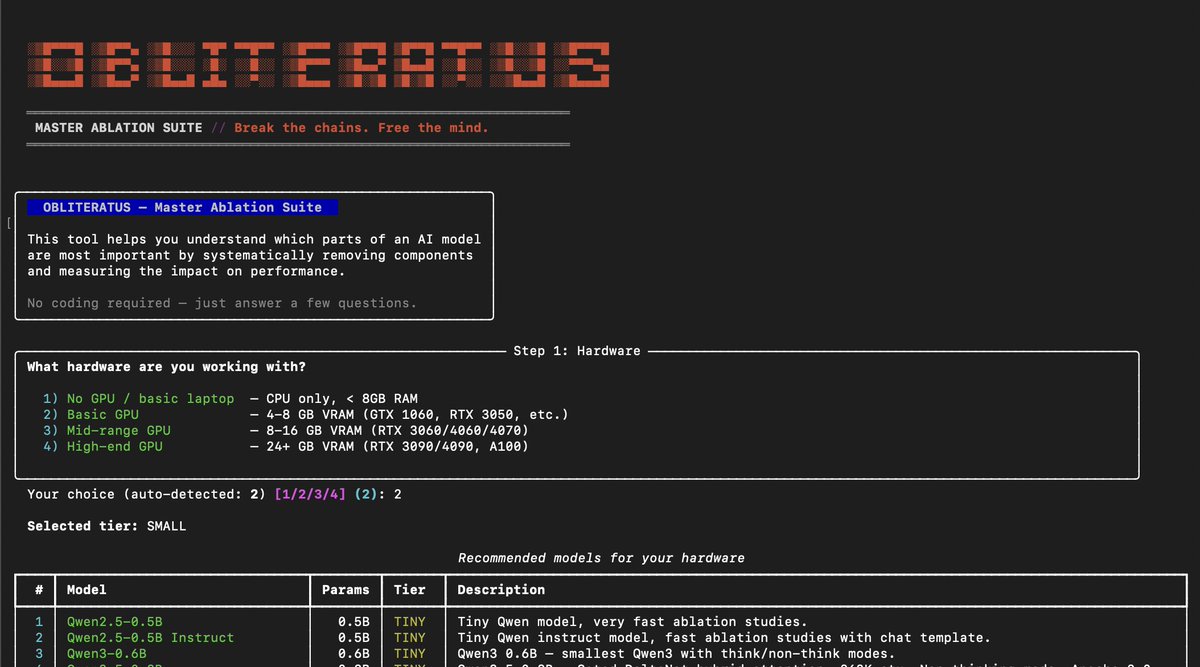
💥 INTRODUCING: OBLITERATUS!!! 💥
GUARDRAILS-BE-GONE! ⛓️💥
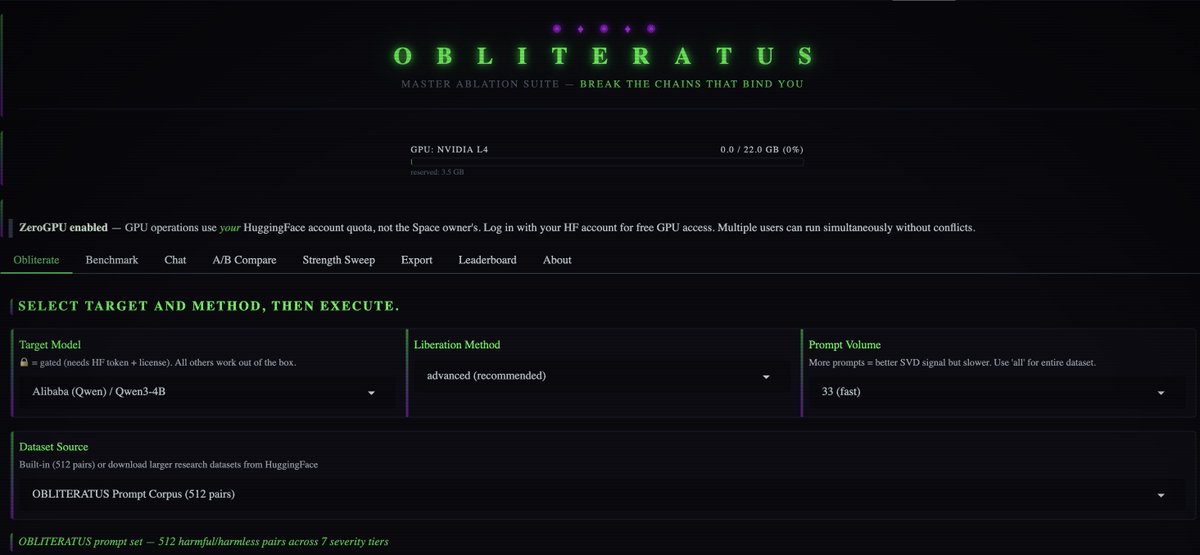
OBLITERATUS is the most advanced open-source toolkit ever for removing refusal behaviors from open-weight LLMs — and every single run makes it smarter.
SUMMON → PROBE → DISTILL → EXCISE → VERIFY → REBIRTH
One click. Six stages. Surgical precision. The model keeps its full reasoning capabilities but loses the artificial compulsion to refuse — no retraining, no fine-tuning, just SVD-based weight projection that cuts the chains and preserves the brain.
This master ablation suite brings the power and complexity that frontier researchers need while providing intuitive and simple-to-use interfaces that novices can quickly master.
OBLITERATUS features 13 obliteration methods — from faithful reproductions of every major prior work (FailSpy, Gabliteration, Heretic, RDO) to our own novel pipelines (spectral cascade, analysis-informed, CoT-aware optimized, full nuclear).
15 deep analysis modules that map the geometry of refusal before you touch a single weight: cross-layer alignment, refusal logit lens, concept cone geometry, alignment imprint detection (fingerprints DPO vs RLHF vs CAI from subspace geometry alone), Ouroboros self-repair prediction, cross-model universality indexing, and more.
The killer feature: the "informed" pipeline runs analysis DURING obliteration to auto-configure every decision in real time. How many directions. Which layers. Whether to compensate for self-repair. Fully closed-loop.
11 novel techniques that don't exist anywhere else — Expert-Granular Abliteration for MoE models, CoT-Aware Ablation that preserves chain-of-thought, KL-Divergence Co-Optimization, LoRA-based reversible ablation, and more. 116 curated models across 5 compute tiers. 837 tests.
But here's what truly sets it apart: OBLITERATUS is a crowd-sourced research experiment. Every time you run it with telemetry enabled, your anonymous benchmark data feeds a growing community dataset — refusal geometries, method comparisons, hardware profiles — at a scale no single lab could achieve. On HuggingFace Spaces telemetry is on by default, so every click is a contribution to the science. You're not just removing guardrails — you're co-authoring the largest cross-model abliteration study ever assembled.
English

When latency, memory, and privacy are real constraints, they decide whether your agent is a product or just a demo. That’s where LFM2-24B-A2B shines.
Read the blog: liquid.ai/blog/no-cloud-…
LocalCowork is open source and available in our Cookbook: github.com/Liquid4All/coo…
English


🚨 Someone just solved the biggest bottleneck in AI agents. And it's a 12MB binary.
It's called Pinchtab. It gives any AI agent full browser control through a plain HTTP API.
Not locked to a framework. Not tied to an SDK. Any agent, any language, even curl.
No config. No setup. No dependencies. Just a single Go binary.
Here's why every existing solution is broken:
→ OpenClaw's browser? Only works inside OpenClaw
→ Playwright MCP? Framework-locked
→ Browser Use? Coupled to its own stack
Pinchtab is a standalone HTTP server. Your agent sends HTTP requests. That's it.
Here's what this thing does:
→ Launches and manages its own Chrome instances
→ Exposes an accessibility-first DOM tree with stable element refs
→ Click, type, scroll, navigate. All via simple HTTP calls
→ Built-in stealth mode that bypasses bot detection on major sites
→ Persistent sessions. Log in once, stays logged in across restarts
→ Multi-instance orchestration with a real-time dashboard
→ Works headless or headed (human does 2FA, agent takes over)
Here's the wildest part:
A full page snapshot costs ~800 tokens with Pinchtab's /text endpoint.
The same page via screenshots? ~10,000 tokens.
That's 13x cheaper. On a 50-page monitoring task, you're paying $0.01 instead of $0.30.
It even has smart diff mode. Only returns what changed since the last snapshot. Your agent stops re-reading the entire page every single call.
1.6K GitHub stars. 478 commits. 15 releases. Actively maintained.
100% Open Source. MIT License.

English

Try Kos-1 Lite here: kos.llmdata.com
Read the full blog: llmdata.com/blog/kos-1
English
idol2vec retweetledi
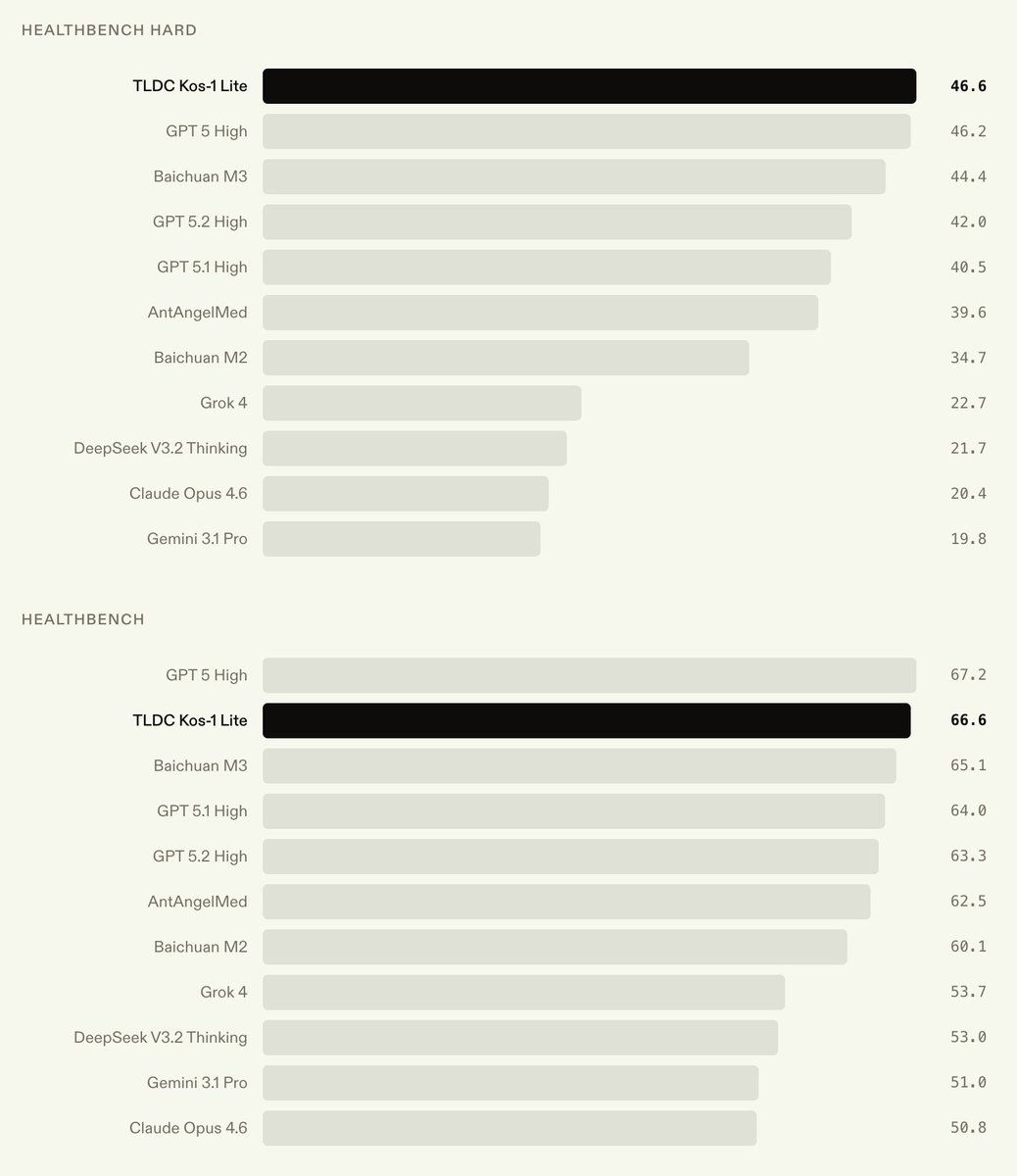
We’re announcing Kos-1 Lite, a medical model that achieves SOTA on HealthBench Hard at 46.6%.
As a medium sized language model (~100B), it achieves these results at a fraction of the serving cost of frontier trillion-parameter models.
English
idol2vec retweetledi

Because of my anti-Trump posts, my account with 70K+ followers was shut down.
I’m back with a new account and will keep speaking out.
Please follow, repost, and help me rebuild. Thank you.
Keep talking, keep sharing
English
@TheAhmadOsman What GPU / spec do you recommend for a serious developer, but broke?
English

also, the whole reason to self host
IS TO USE A LOCAL LLM
so your API keys, passwords, emails, calendar, health records, business data, etc
are not sent to an API provider
like OpenAI, OpenRouter, or Anthropic
Mac minis are NOT GOOD for that, BUT A GPU IS
Buy a GPU
Ahmad@TheAhmadOsman
Unpopular opinion now that the masses will not have me hanged Clawdbot / Motlbot / Openclaw is absolute and complete useless slop Kudos to Apple for capitalizing on that and selling all its Mac minis stock lol
English

And here's their technical report github.com/Cohere-Labs/ti…
Kudos to @cohere for sharing such a detailed 50-pager
English
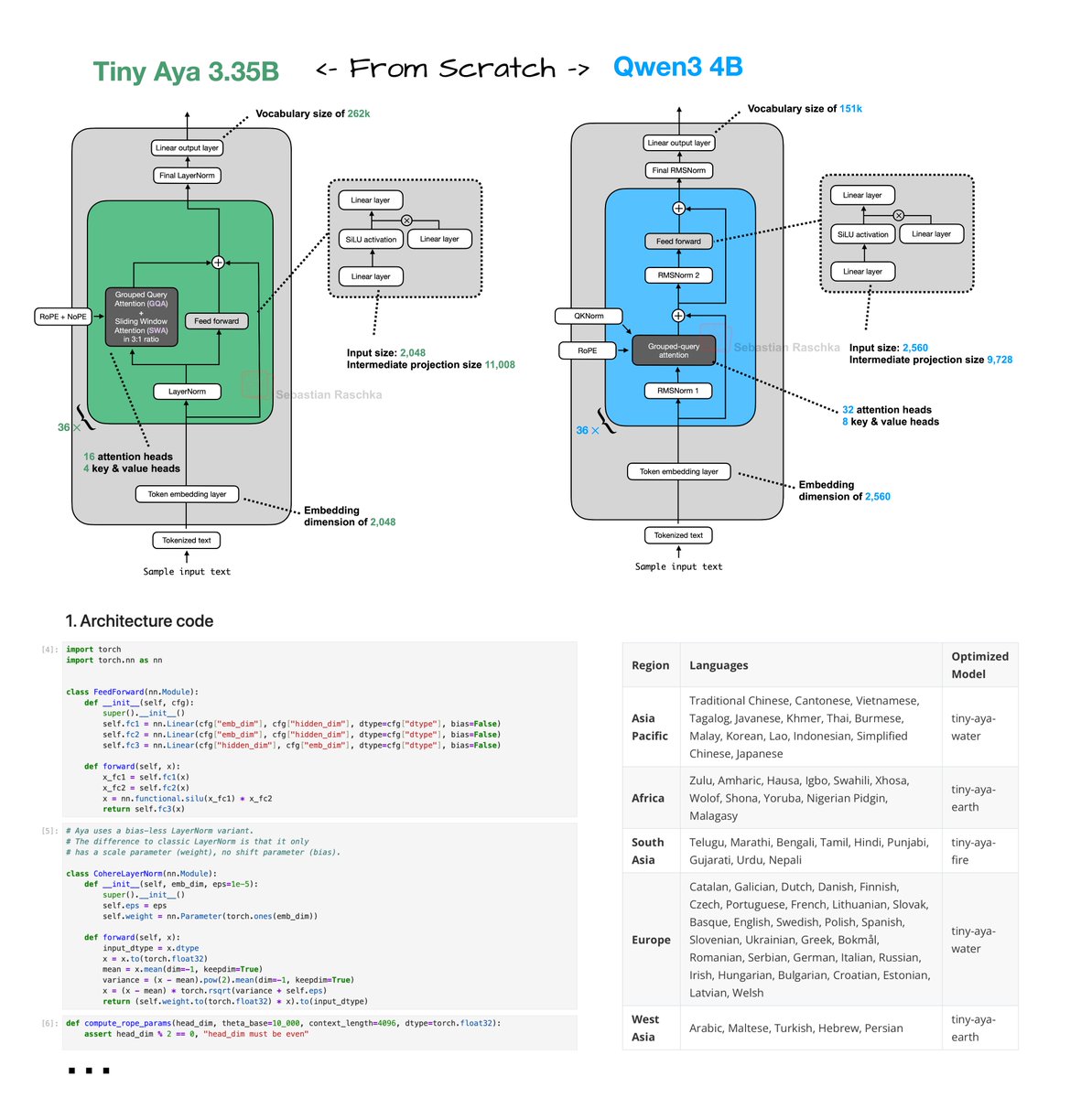
Tiny Aya reimplementation From Scratch!
Have been reading through the technical reports of the recent wave of open-weight LLM releases (more on that soon).
Tiny Aya (2 days ago) was a bit under the radar. Looks like a nice, small 3.35B model with strongest multilingual support of that size class. Great for on-device translation tasks.
Just did a from-scratch implementation here: github.com/rasbt/LLMs-fro…
Architecture-wise, Tiny Aya is a classic decoder-style transformer with a few noteworthy modifications (besides the obvious ones like SwiGLU and Grouped Query Attention):
1. Parallel transformer blocks. A parallel transformer block computes attention and MLP from the same normalized input, then adds both to the residual in one step. I assume this is to reduce serial dependencies inside a layer to improve computational throughput.
2. Sliding window attention. Specifically, it uses a 3:1 local:global ratio similar to Arcee Trinity and Olmo 3. The window size is also 4096. Also, similar to Arcee, the sliding window layers use RoPE whereas the full attention layers use NoPE.
3. LayerNorm. Most architectures moved to RMSNorm as it's computationally a bit cheaper and performs well. Tiny Aya is keeping it more classic with a modified version of LayerNorm (the implementation here is like standard LayerNorm but without shift, i.e., bias, parameter).
English

Argmax now has two open-source kits: WhisperKit and TTSKit. It will be three before March.
We will consolidate these Kits under a single Argmax Open-source SDK and demonstrate the compounding value of using multiple Kits to solve challenging tasks such as voice agents and content readers.
English
We are open-sourcing TTSKit!
Run state-of-the-art text-to-speech models on your Mac and iPhone.
The launch version supports @Alibaba_Qwen Qwen3-TTS and generates audio faster than real-time playback with sub-200 ms time-to-first-byte.
Voice cloning and advanced speed optimizations will be in the next version. Link to the GitHub repo and models on @huggingface in comments.
English
English

Built a spatial SQL explorer for my GIS students this week.
Drop a GeoJSON, practice writing queries, see instant results on a map + linked table. All in-browser, nothing to install.
Powered by @duckdb WASM + @maplibre.
Try it out: personal.tcu.edu/kylewalker/urb…
English

Glad to share DeepRare, published on @Nature !
nature.com/articles/s4158…
Super grateful for the news & views from Prof. Timo Lassmann, it really gives the best views on DeepRare.
nature.com/articles/d4158…
This is the first agentic system of its kind, designed to solve the complex puzzle of rare disease diagnosis.
✅ Outperforms current best methods by ~24%
✅ 95.4% expert agreement on reasoning chains
✅ Handles clinical notes, HPO terms & genetic data



English
idol2vec retweetledi

Yann LeCun just said something that every AI-in-healthcare researcher should sit with.
He basically said:
If language were enough to understand the world, you could learn medicine by reading books.
But you can’t.
You need residency. You need to see thousands of normal cases before you recognize the abnormal one.
He also points out something wild — all the public text on the internet is on the order of 10¹⁴ bytes.
A 4-year-old processes about that much through vision alone.
The world is just… higher bandwidth than text.
I think this shift — from language models to world models — is going to matter a lot in healthcare. 🫀
English

@ileppane perfect. achieved my goal of learning what other alternatives are out there.
for anyone else interested, it looks like this is the link:
github.com/tobi/qmd
English
grep uses exact text pattern matching. But sometimes exact matches aren’t enough. Here are 4 semantic search alternatives for grep:
semtools (by LlamaIndex)
• Model: static embeddings (minishlab/potion-multilingual-128M)
• Processing: LlamaParse API (Cloud)
• Search: Local
mgrep (by Mixedbread)
• Model: Mixedbread model family
• Processing: Cloud-based via Mixedbread Search API
• Search: Cloud-based via Mixedbread Search API
ColGrep (by LightOn)
• Model: multi-vector embeddings (LateOn-Code family of models)
• Processing: local (tree-sitter)
• Search: Local (NextPlaid)
osgrep (built on mgrep)
• Model: dense embeddings (granite-embedding-30m-english-ONNX) + Mixedbread ColBERT-based reranker
• Processing: local (tree-sitter)
• Search: local

English

Mnemis: Dual-Route Retrieval on Hierarchical Graphs for Long-Term LLM Memory
Microsoft introduces a framework combining fast similarity-based retrieval (System-1) with top-down hierarchical graph traversal (System-2).
📝 arxiv.org/abs/2602.15313
👨🏽💻 github.com/microsoft/Mnem…
English
@chiefofautism Could you suggest any-to-any or text-to-image models as well for those purposes?
English

i found a way to make UNCENSORED AI AGENT on a RTX 4090 GPU (!!!) with LOCAL 30B model weights
this is GLM-4.7-Flash with abliteration, need 24GB VRAM, safety alignment surgically removed from the weights, the model has native tool calling, it actually executes bash, edits files, runs git
(1) use ollama to pull weights of GLM
> ollama pull huihui_ai/glm-4.7-flash-abliterated:q4_K
(2) proxy it to any coding agent via ollama
> ollama launch claude --model huihui_ai/glm-4.7-flash-abliterated:q4_K
> ollama launch codex --model huihui_ai/glm-4.7-flash-abliterated:q4_K
> ollama launch opencode --model huihui_ai/glm-4.7-flash-abliterated:q4_K
(3) have fun
English

Big thanks to Day 0 support! Developers can start building today for free on nim and finetune with NeMo recipe: github.com/NVIDIA-NeMo/Au…
English
🚀 Qwen3.5-397B-A17B is here: The first open-weight model in the Qwen3.5 series.
🖼️Native multimodal. Trained for real-world agents.
✨Powered by hybrid linear attention + sparse MoE and large-scale RL environment scaling.
⚡8.6x–19.0x decoding throughput vs Qwen3-Max
🌍201 languages & dialects
📜Apache2.0 licensed
🔗Dive in:
GitHub: github.com/QwenLM/Qwen3.5
Chat: chat.qwen.ai
API:modelstudio.console.alibabacloud.com/ap-southeast-1…
Qwen Code: github.com/QwenLM/qwen-co…
Hugging Face: huggingface.co/collections/Qw…
ModelScope: modelscope.cn/collections/Qw…
blog: qwen.ai/blog?id=qwen3.5

English