
rotem
110 posts

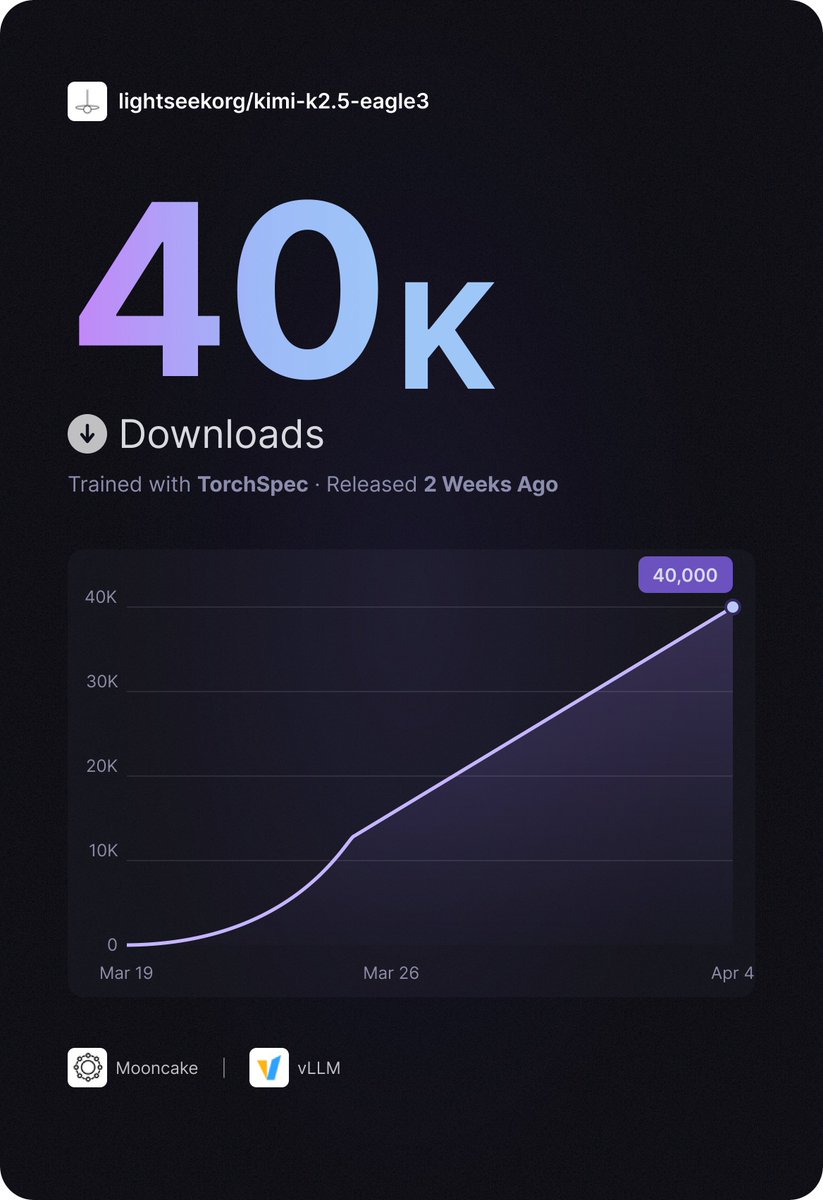
Huge milestone for kimi-k2.5-eagle3 reaching 40K downloads on Hugging Face, especially in just two weeks 🚀🚀🚀
It is also a great signal for the growing adoption of speculative decoding in production.
LightSeek Foundation@lightseekorg
🚀TorchSpec has been live for 2 weeks — and kimi-k2.5-eagle3 just hit 40K downloads on HuggingFace! Thanks to @KT_Project_AI Team and @vllm_project Team for the amazing collaboration. Links in comments.
English
English

🚀TorchSpec has been live for 2 weeks — and kimi-k2.5-eagle3 just hit 40K downloads on HuggingFace!
Thanks to @KT_Project_AI Team and @vllm_project Team for the amazing collaboration.
Links in comments.
English

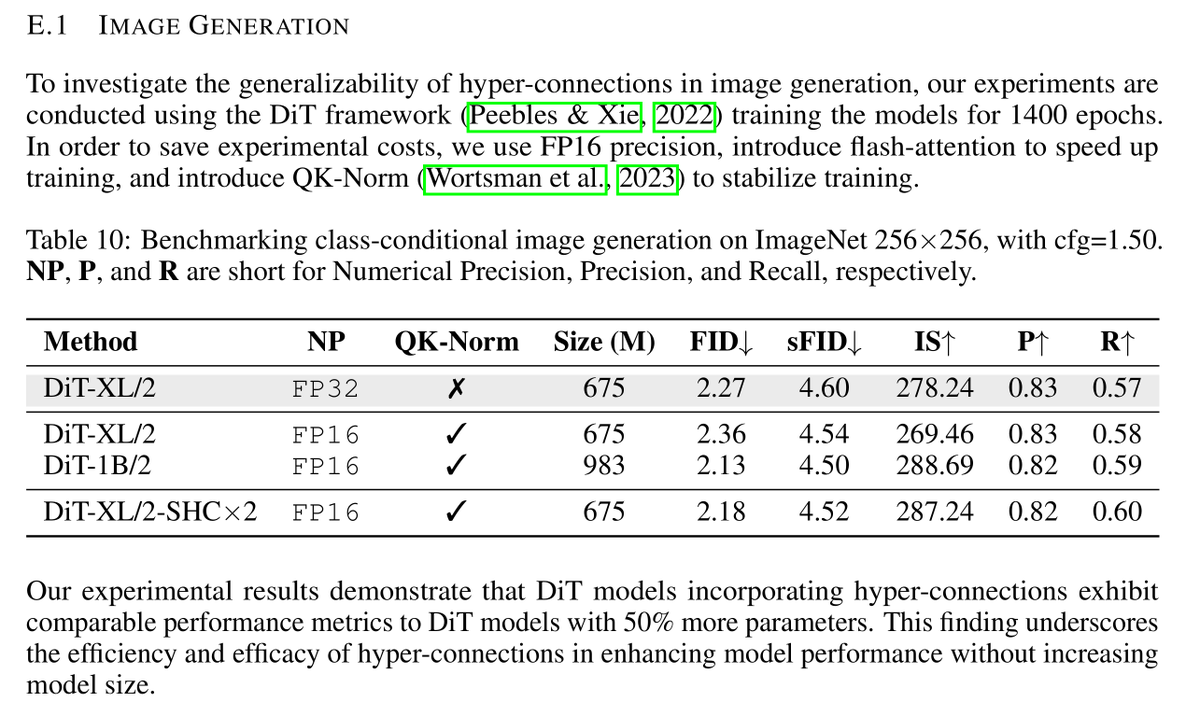
0.9+ FID with a 150M model, 1-step pixel space😅
Jiawei Yang@JiaweiYang118
I guess I just have some 1-step pixel space generation models with 1.3 FID on ImageNet256?
English

🚀 Introducing Qwen-Image-2.0 — our next-gen image generation model!
🎨 Your imagination, unleashed.
✨ Type a paragraph → get a pro slides
✨ Describe a scene → get photoreal 2K magic
✨ Add text → it just works (no more glitchy letters!)
✨ Key upgrades:
✅ Professional typography (1K-token prompts for slides, posters & comics)
✅ 2K native resolution with stunning detail
✅ Flawless text rendering + unified generation/editing
✅ Lighter architecture = faster inference
Try it now → chat.qwen.ai/?inputFeature=…
Full details → qwen.ai/blog?id=qwen-i…

English

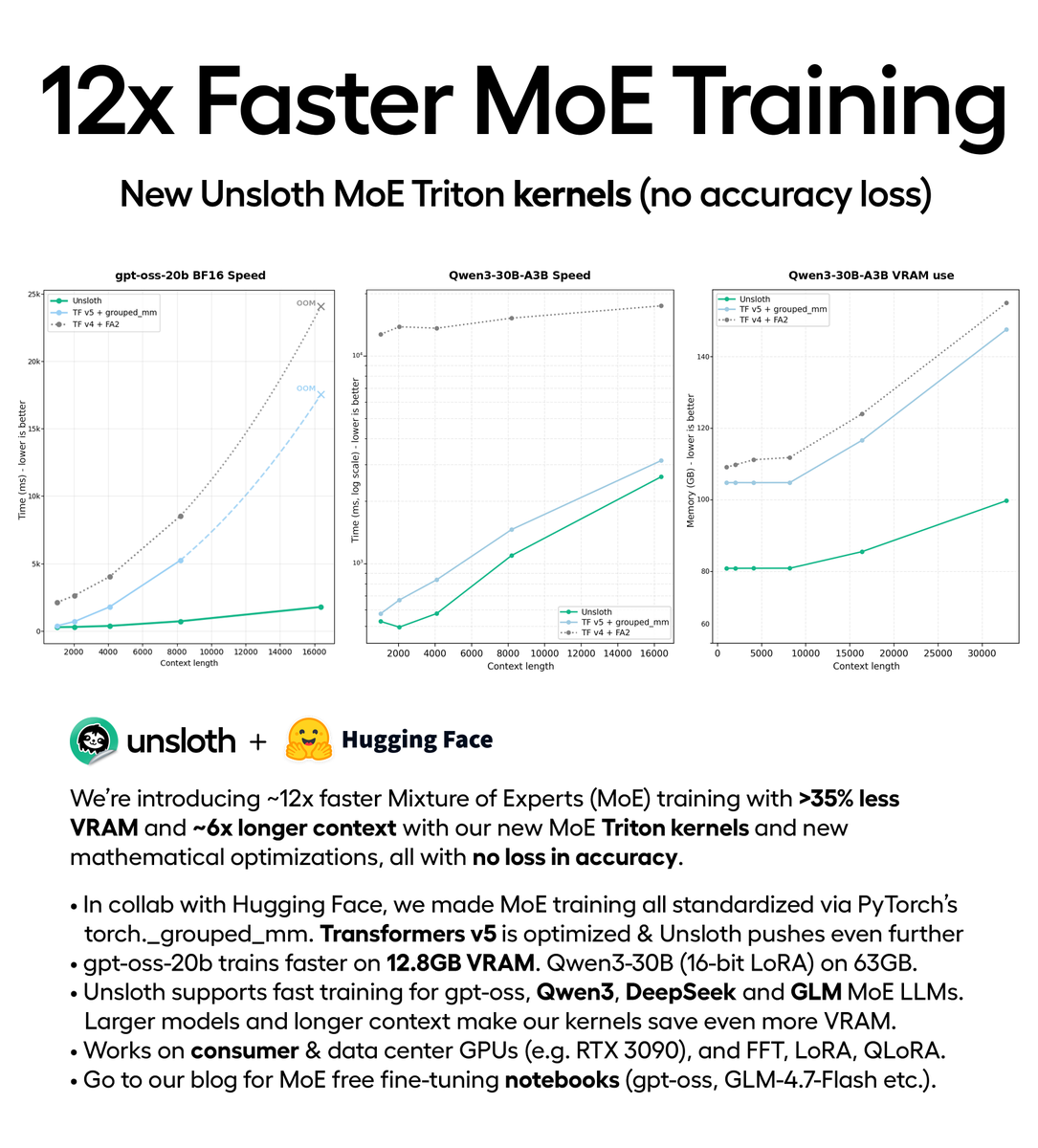
You can now train MoE models 12× faster with 35% less VRAM via our new Triton kernels (no accuracy loss).
Train gpt-oss locally on 12.8GB VRAM.
In collab with @HuggingFace, Unsloth trains DeepSeek, Qwen3, GLM faster.
Repo: github.com/unslothai/unsl…
Blog: unsloth.ai/docs/new/faste…
English

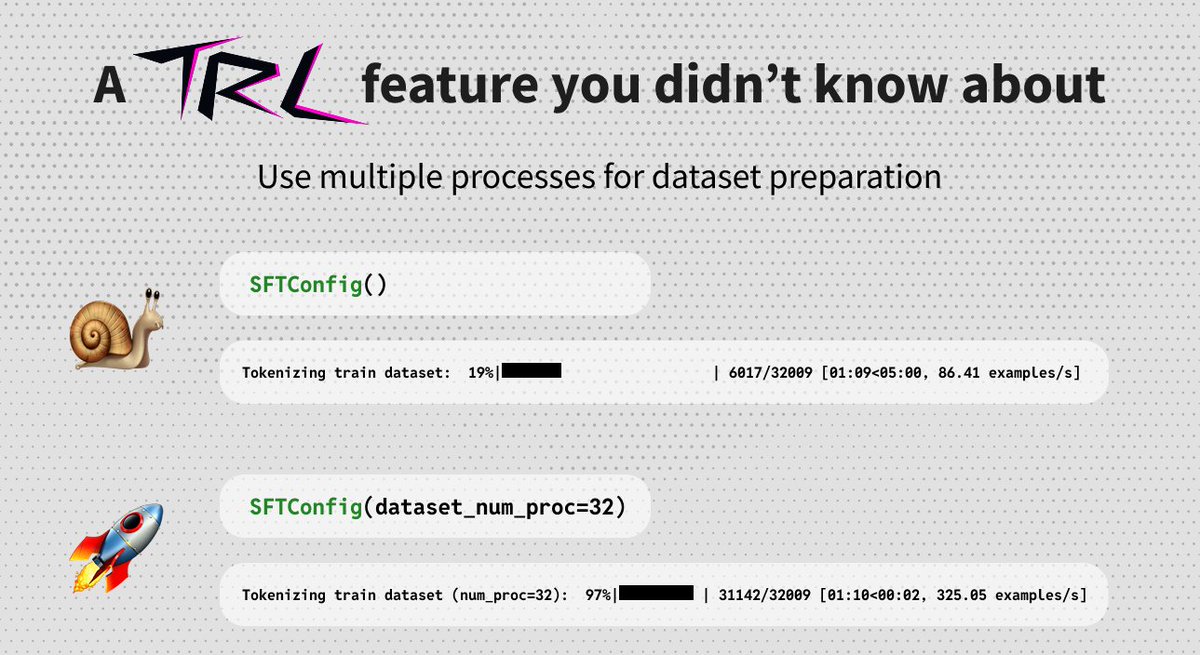
sft, dpo, reward modeling, they all involve dataset preparation
one simple arg can significantly speedup this stage
English

@UnslothAI @vllm_project when unsloth is quiet for a two weeks you know something big is cooking
English
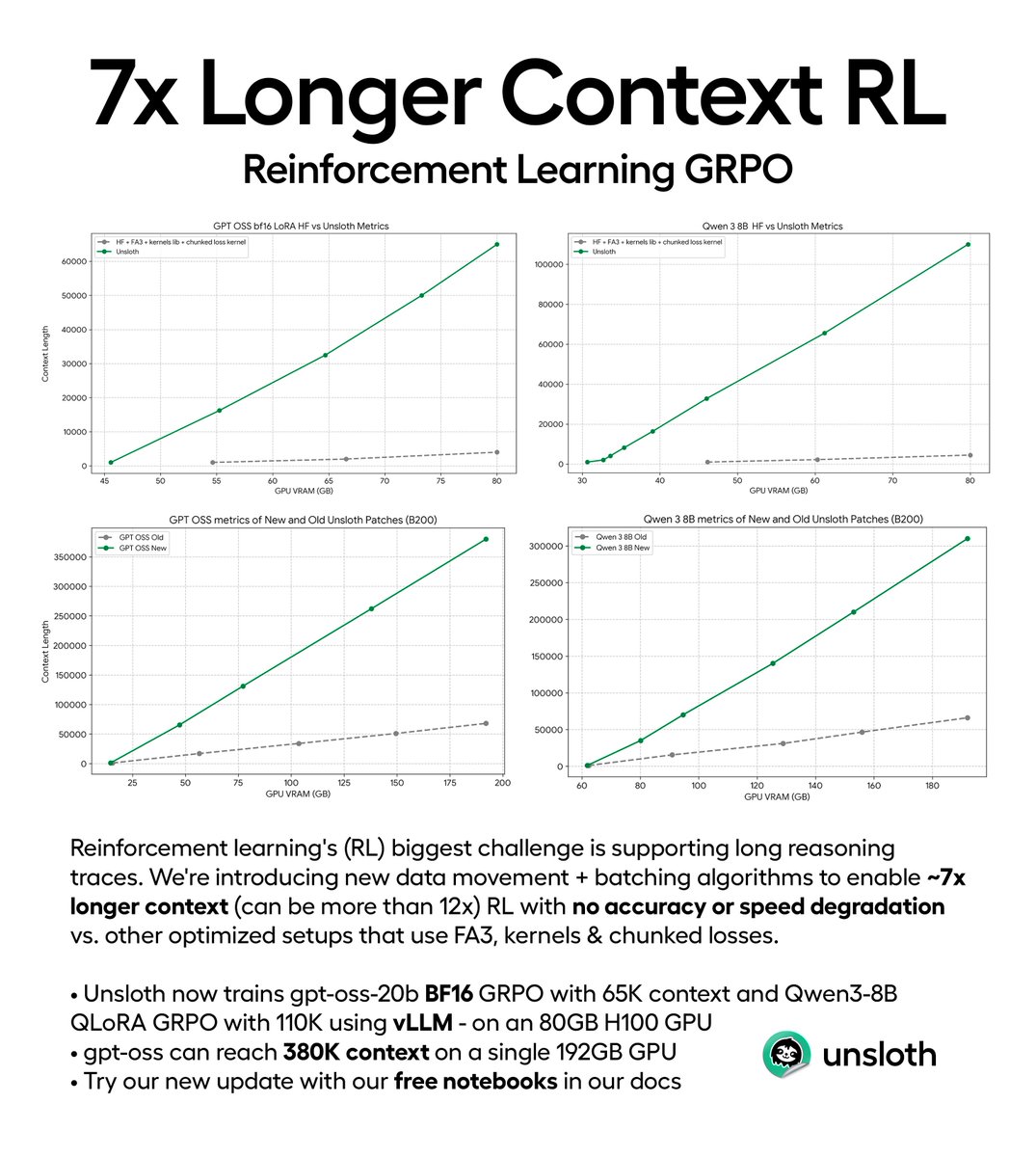
You can now do reinforcement learning training with 7× longer context and no accuracy loss, via our new batching algorithms.
Long reasoning chains in RL are costly, but now we enable you to train gpt-oss with GRPO & reach 380K context on a 192GB GPU.
unsloth.ai/docs/new/grpo-…
English
@classiclarryd @ChrisJMcCormick amazing!
will i be able to take this adam to completely different training like diffusion?
English

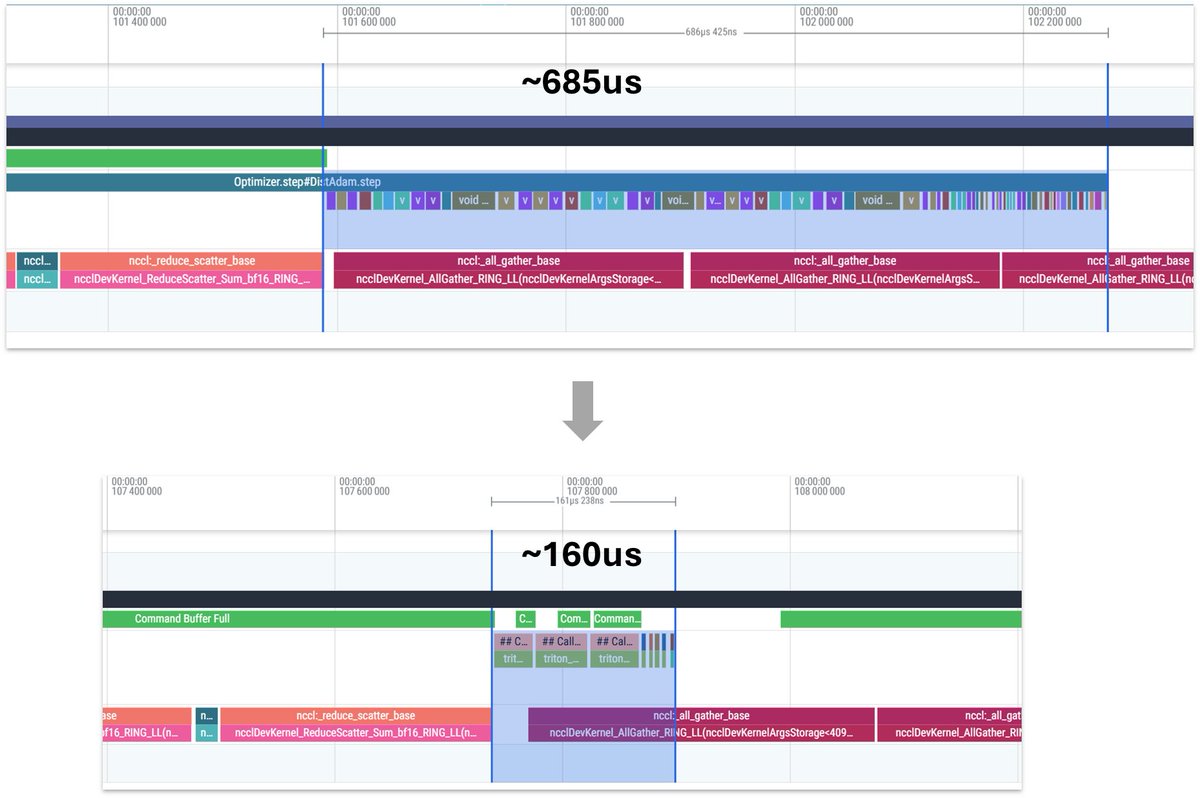
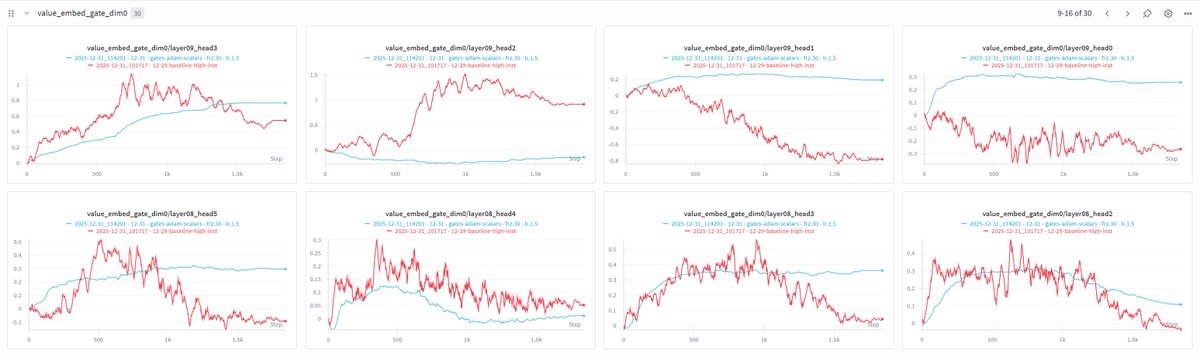
New NanoGPT Speedrun WR at 113.7 (-1.4s) from @ChrisJMcCormick, w/ param bank to centralize certain per-layer params, optimized Adam, ema buffer precision increase, and gate matrices from Muon to Adam. Scientists claim records must stop after reaching 0s. github.com/KellerJordan/m…

English
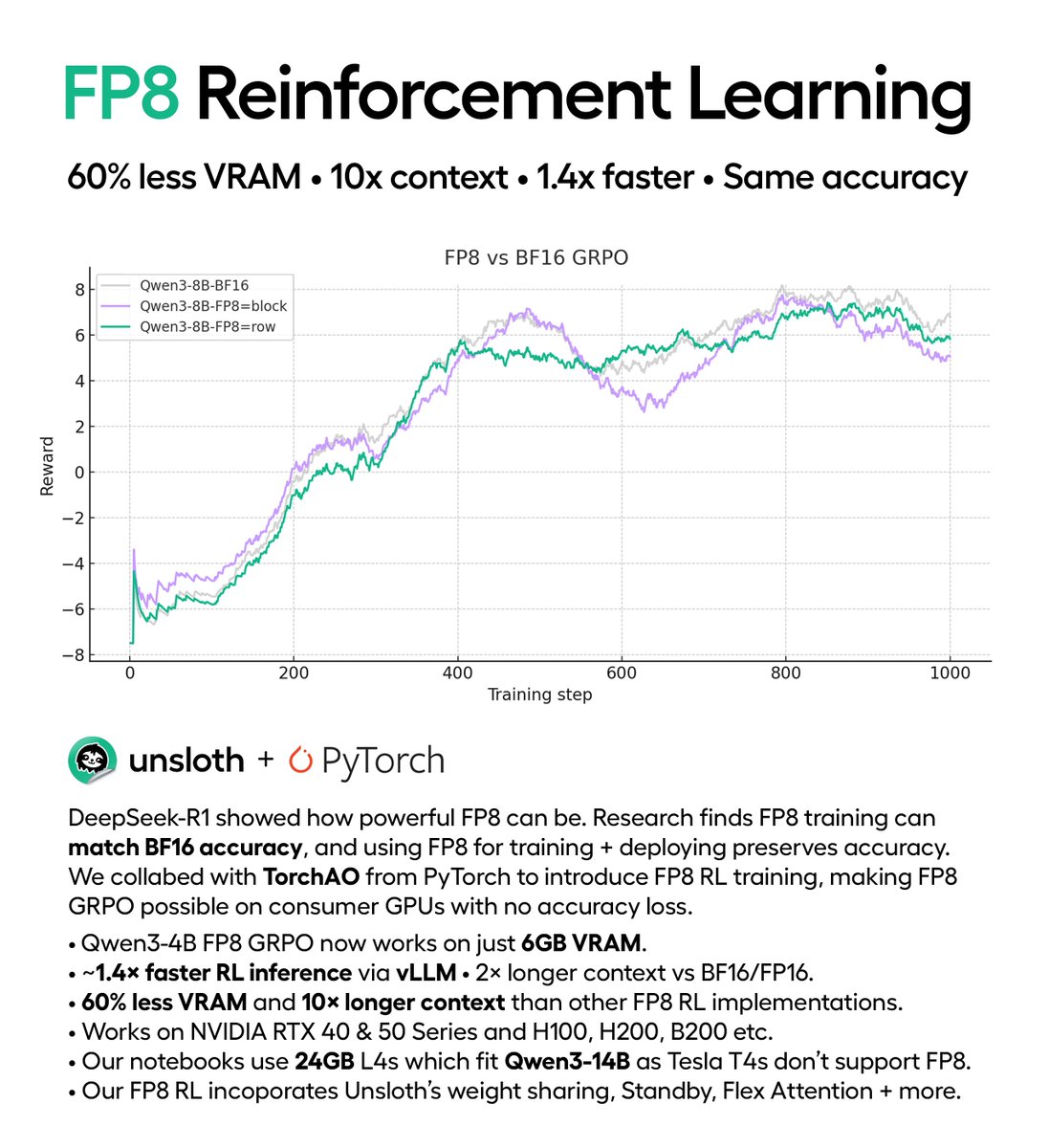
You can now run FP8 reinforcement learning on consumer GPUs!
Try DeepSeek-R1’s FP8 GRPO at home using only a 5GB GPU.
Qwen3-1.7B fits in 5GB VRAM.
We collabed with PyTorch to make FP8 RL inference 1.4× faster.
Unsloth: 60% less VRAM, 12× longer context.
docs.unsloth.ai/new/fp8-reinfo…
English

🥳🎉Sana-video inference code has been integrated into diffusers! Thanks to @lawrence_cjs @RisingSayak and the team for making it happen. huggingface.co/docs/diffusers…
Enze Xie@xieenze_jr
The training/ Inference code and checkpoints are released. Welcome to try! github.com/NVlabs/Sana
English
@Alibaba_Qwen will training vlm support soon images with any resolution?
English
You can now run Qwen3-VL locally with Unsloth AI.
👇Fine-tune & RL via free notebooks.
Unsloth AI@UnslothAI
You can now run Qwen3-VL locally! 💜 Run the 235B variant for SOTA vision/OCR on 128GB unified memory (dynamic 4-bit). Includes our chat template fixes. Qwen3-VL-2B runs at ~40 t/s on 4GB RAM. Fine-tune & RL via Unsloth free notebooks & export to GGUF. docs.unsloth.ai/models/qwen3-vl
English
@UnslothAI @Alibaba_Qwen goat
support for vllm fast inference for qwen3 vl for rl soon?
English
You can now run Qwen3-VL locally! 💜
Run the 235B variant for SOTA vision/OCR on 128GB unified memory (dynamic 4-bit). Includes our chat template fixes.
Qwen3-VL-2B runs at ~40 t/s on 4GB RAM.
Fine-tune & RL via Unsloth free notebooks & export to GGUF.
docs.unsloth.ai/models/qwen3-vl

English
@paulabartabajo_ @liquidai Thanks for the reply. Benchmarks for agents will be most interesting to me, but the average scores like that post will be great for everyone.
English

English

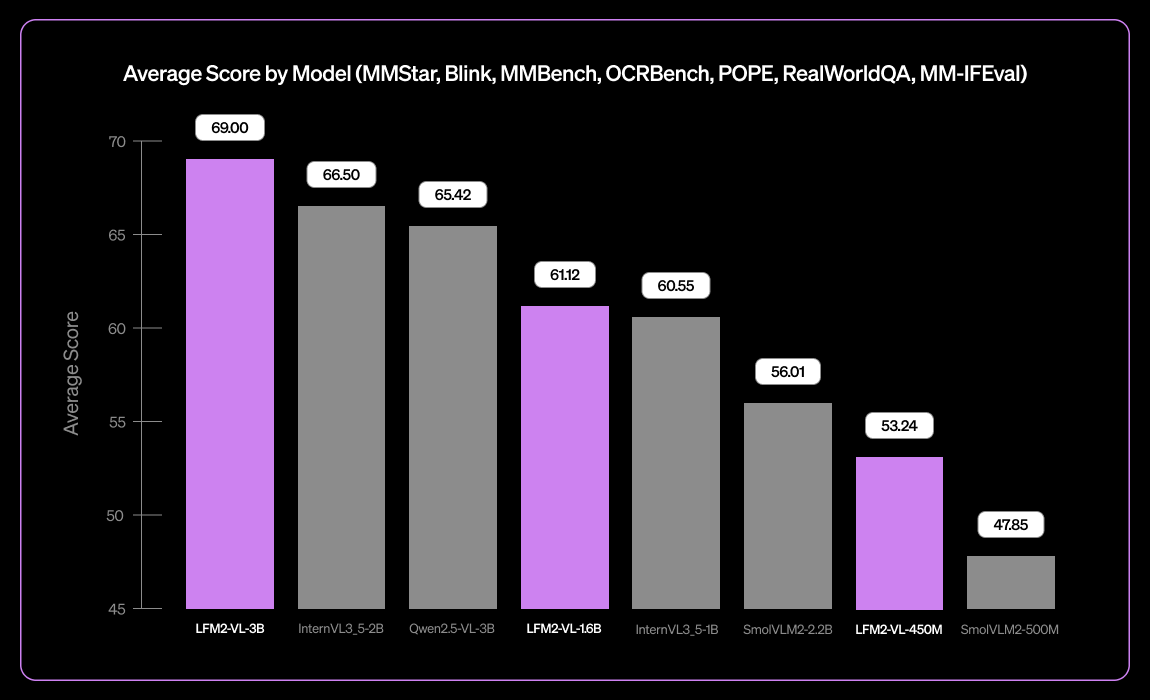
Introducing our new tiny vision language model: LFM2-VL-3B 👀
> Expanded multilingual visual understanding: English, Japanese, French, Spanish, German, Italian, Portuguese, Arabic, Chinese, Korean
> 51.8% on MM-IFEval (instruction following)
> 71.4% on RealWorldQA (real-world understanding)
> Excels in single and multi-image understanding and English OCR
> Low object hallucination rate (POPE benchmark)
Download below 👇
English


