
@MattSchrage @dabit3 That’s great to hear. Thanks for the update. Looking forward to trying the native DeepWiki integration in the CLI 🫡
English
jasonbla
53 posts



The terminal hasn’t changed much since the 1970s. What you do with it has. Introducing Devin for Terminal: everything we learned building Devin, now as a local agent, available right in your shell. And when your work outgrows your laptop, hand it off to the cloud.


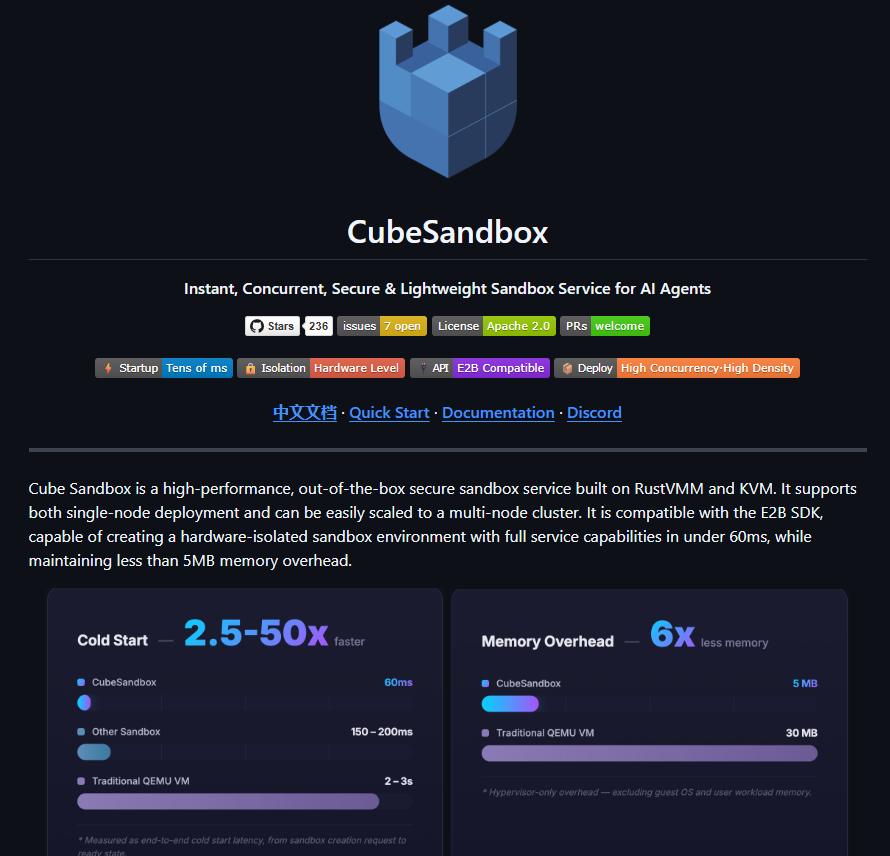




Meet Gemma 4: our new family of open models you can run on your own hardware. Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵





Interesting stat - our enterprise customers have already done more Devin sessions (and more merged Devin PRs) in 2026 than in all of 2025. Not bad for 2-ish months into the year!

