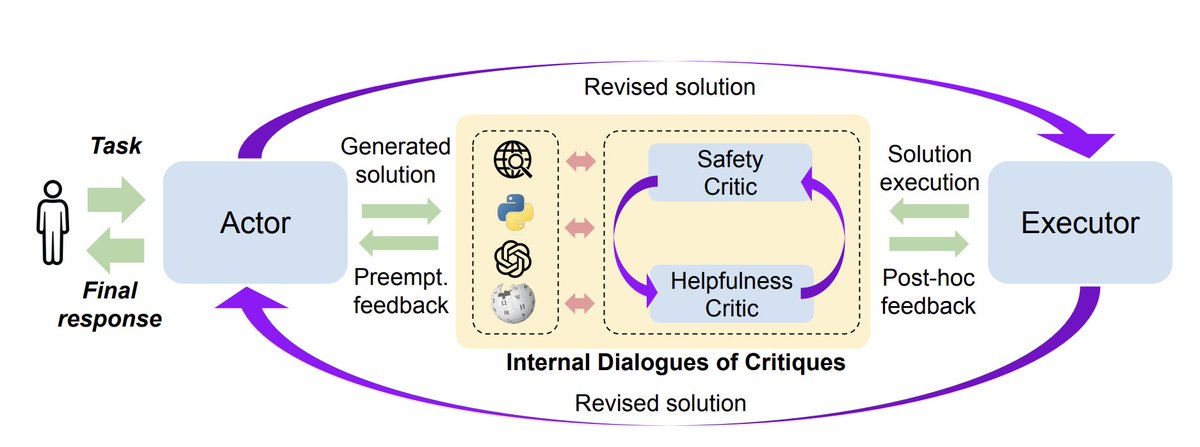
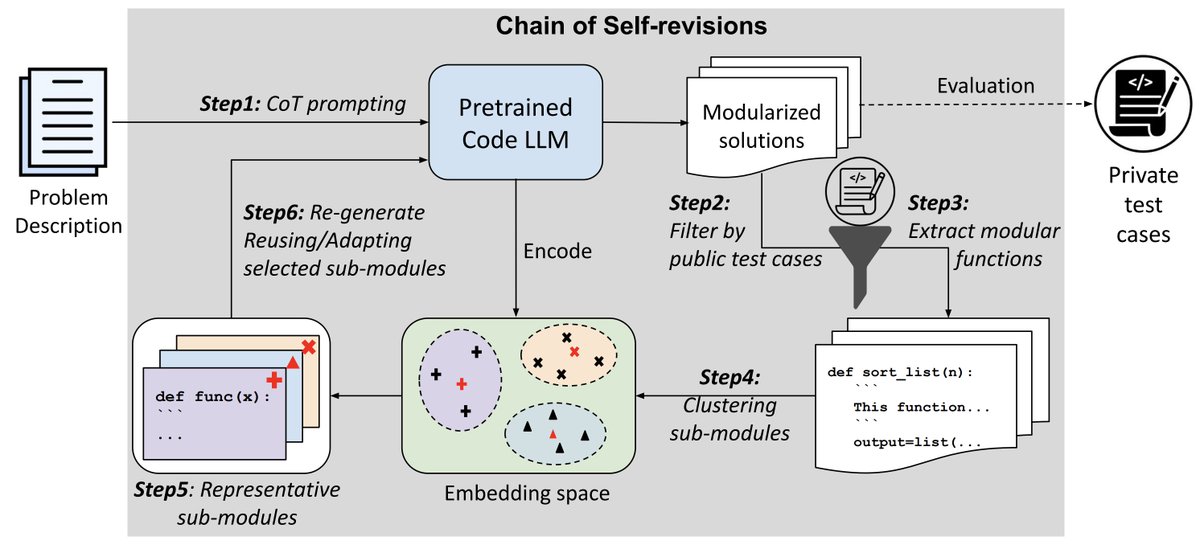
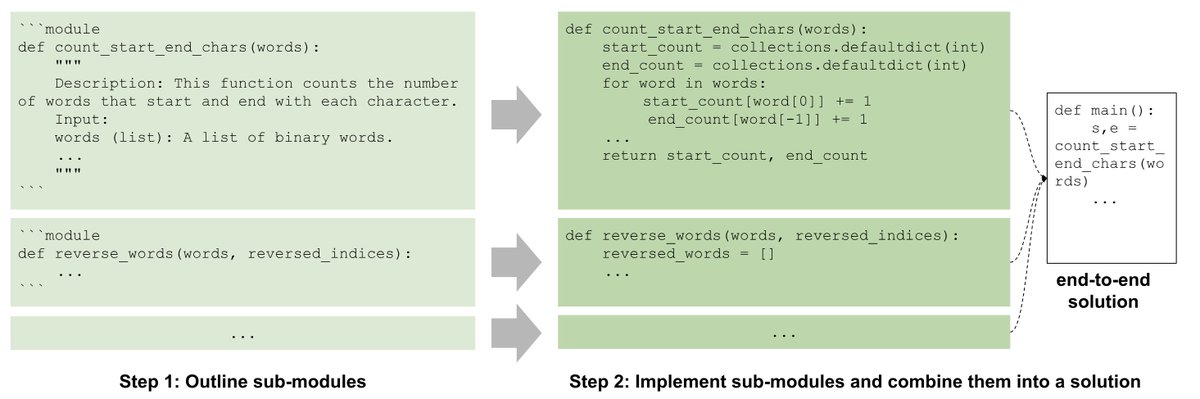
OpenReview should have a new feature to find and track author-AC confidential comments more easily...At this point, I have >230 all replies in my batch. With LLM -augmented reviews, authors seem to flag concerns more often too. The only way I can track the confidential comments now is via emails 😂
English