
@thegenioo Provider “Weights and Biases”. I don’t think it’s at 500 tk/s always since I only got one result like that, but it’s plenty fast. 15 seconds for a fully functioning app.

English
RayBytes
21 posts



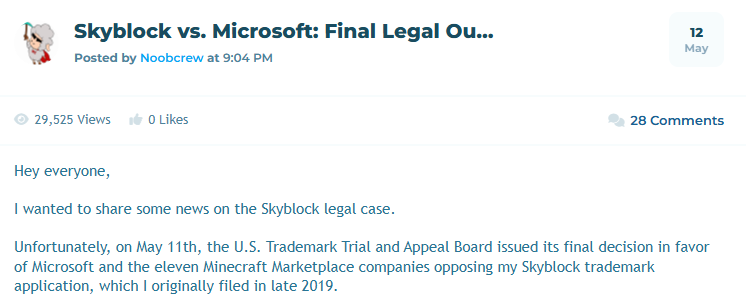


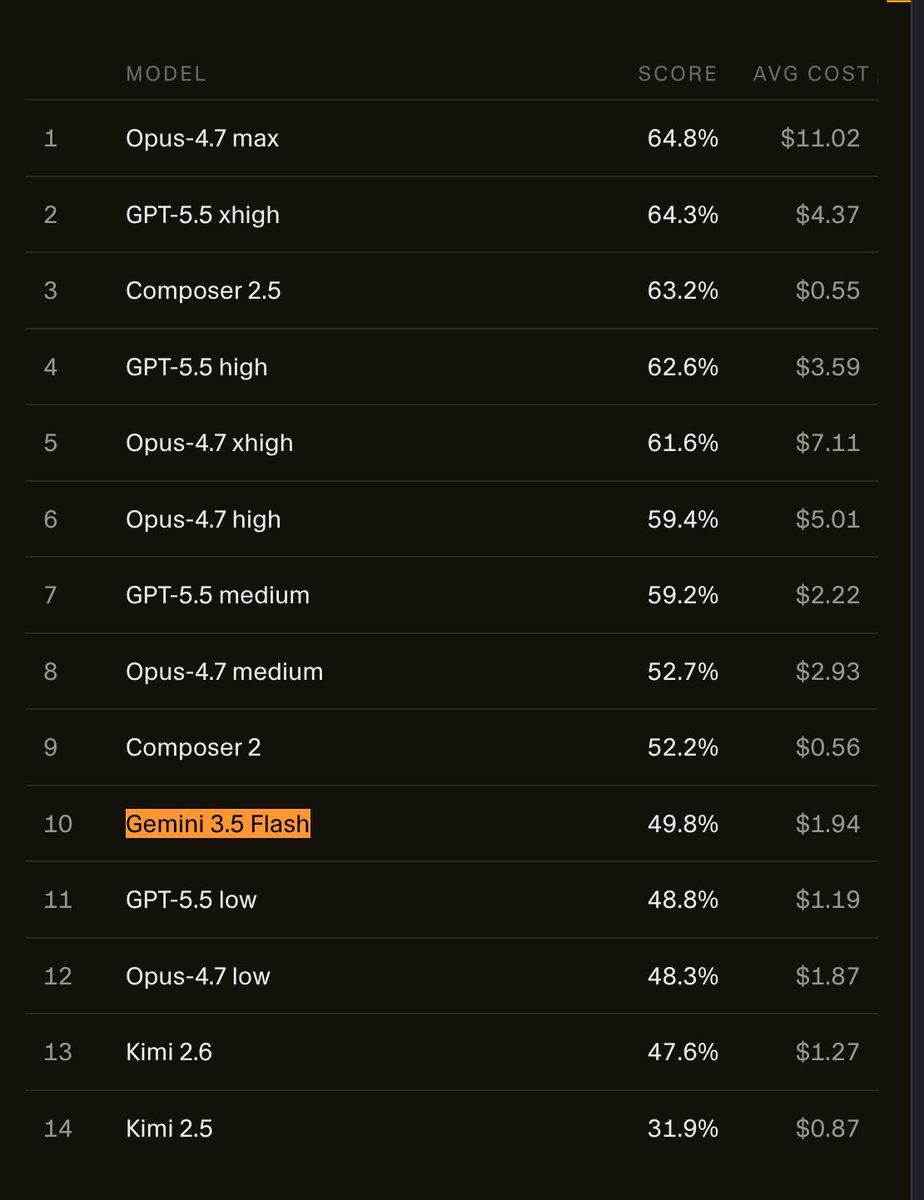
Gemini Flash 3.5 is now on CursorBench, our main coding agent eval. We’ll keep updating the leaderboard as new models come out. cursor.com/evals


Gemini 3.5 Flash Benchmarks


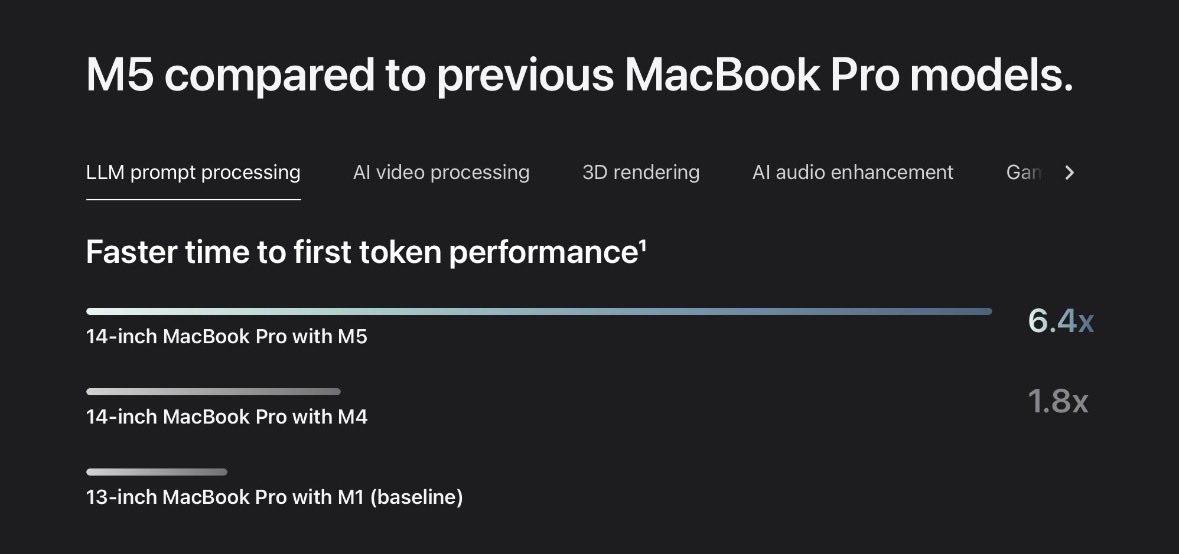
M5 Max cluster 72 CPU and 128 GPU cores, 512GB unified Ram Each MacBook is connected to all the others with Thunderbolt 5 (120Gbit/s). But I’ll have to use Wi-Fi to connect to the cluster











a corporate salesman on an openai paycheck tells you local models aren't there yet. an influencer selling you an API wrapper calls the local AI community on X "cancer." meanwhile we're out here modding communities, helping strangers debug their configs at midnight, fighting spam, pushing open source, and doing it all for free. these people don't want you running models on your own hardware. they want you as a customer. every local install is revenue they lose. every migration from their bloat is a subscription cancelled. don't let corporate noise and engagement bait merchants convert you into their recurring revenue. buy a GPU. compile from source. own your thinking. the community they call cancer is the same community that will help you get started for free while they charge you per token.



