Seppmos
8.5K posts


Seppmos
@seppmos
Building the Company Brain, one at a time | AI Fluent





Always enjoy my conversations with @patrick_oshag Points if you can guess whose office this was filmed in. Also looks like I might need to up my dose of Tirzepatide. 😂




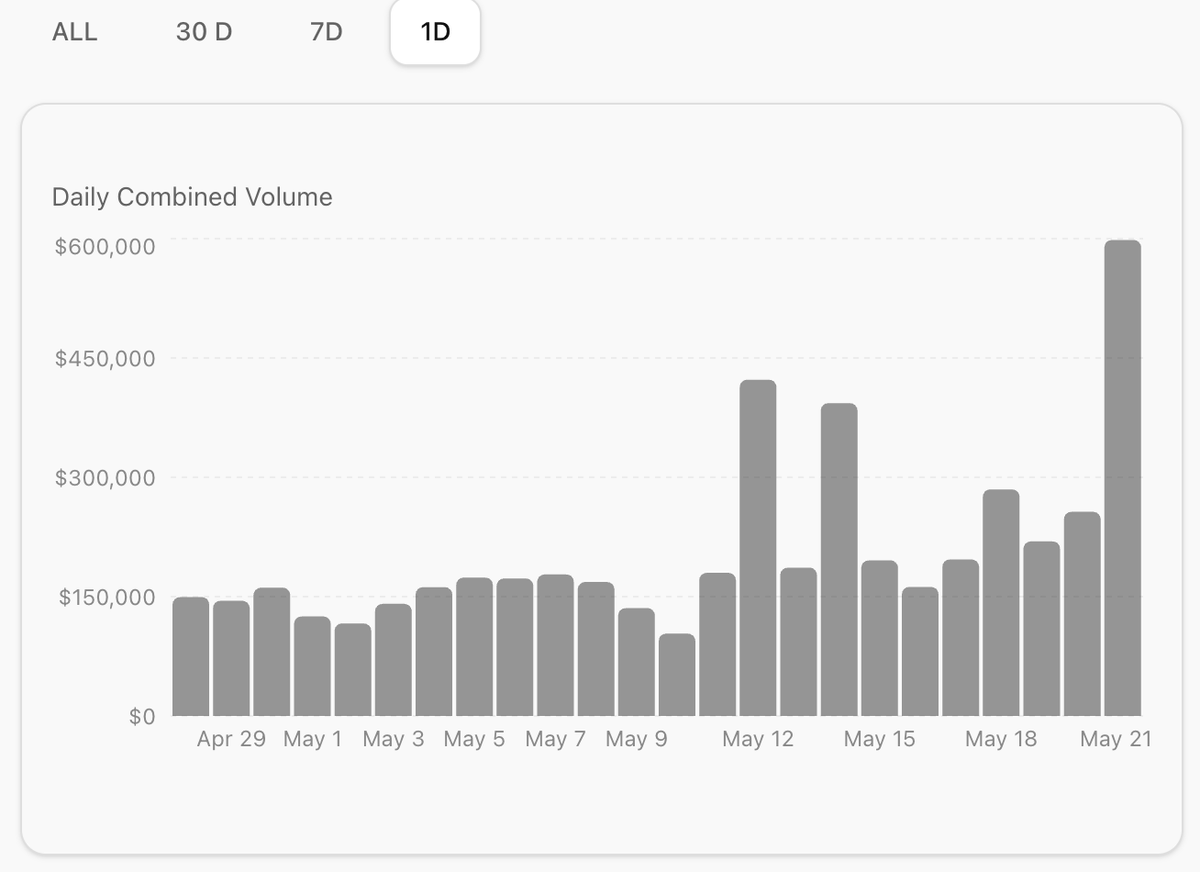
metadao up ~30% from lows zcash up ~100% from lows last month was a great time to plant seeds. now is the time for patience

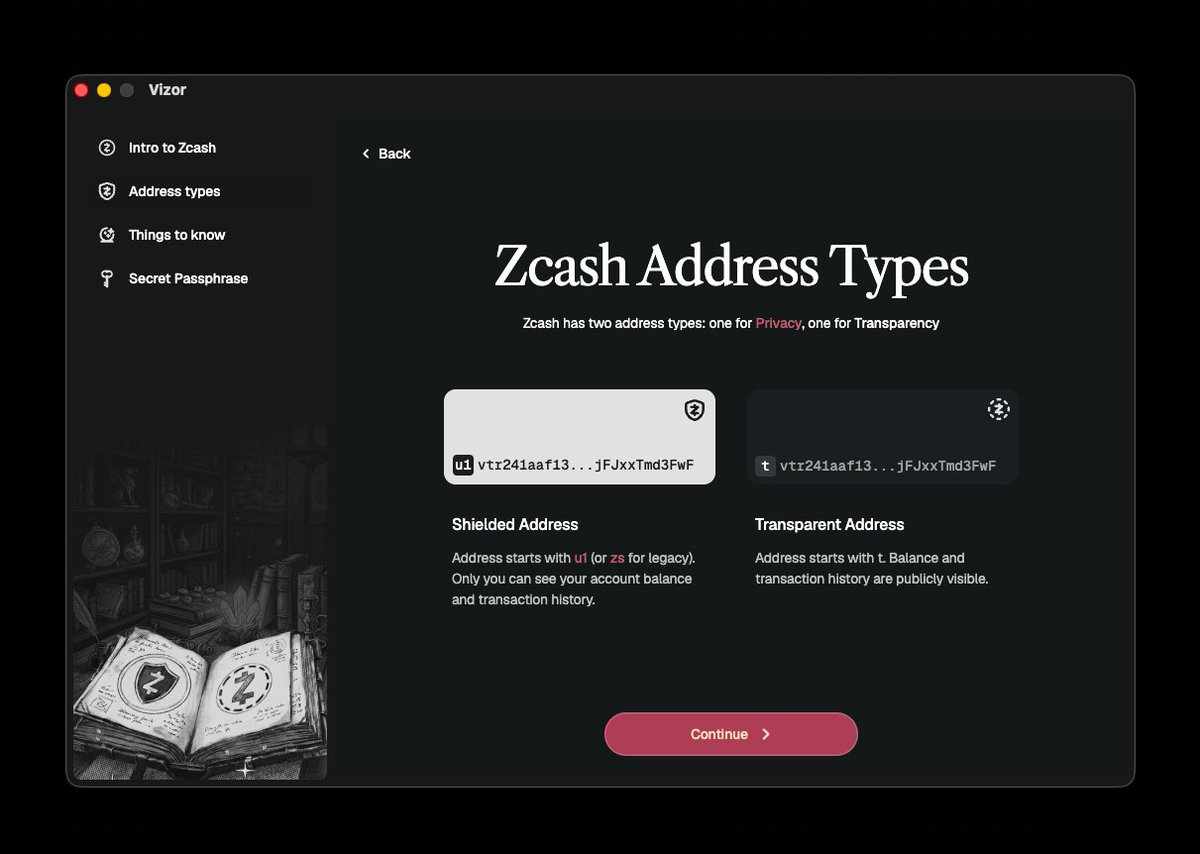
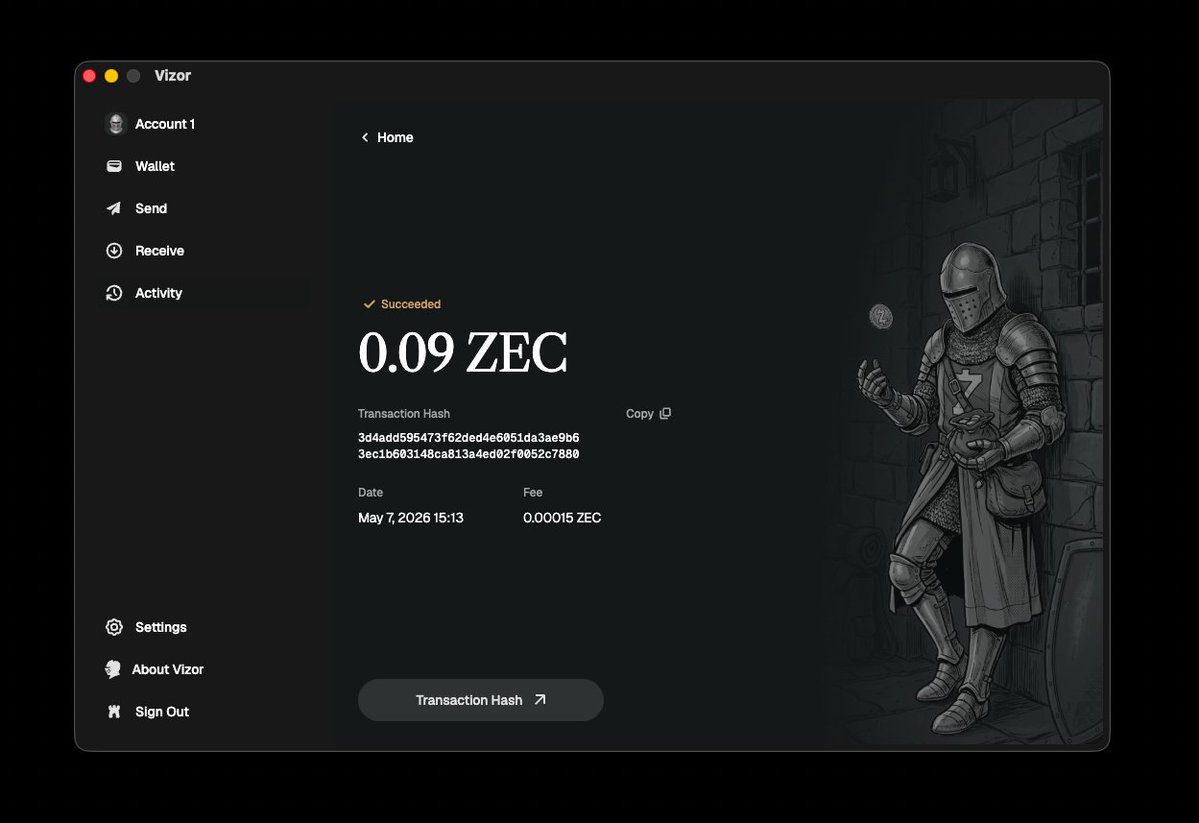
Introducing Vizor. A beautifully crafted @Zcash wallet for your desktop. Multi-account in one wallet. Keystone on day one. Open source. Available now on macOS: vizor.cash



Introducing Vizor. A beautifully crafted @Zcash wallet for your desktop. Multi-account in one wallet. Keystone on day one. Open source. Available now on macOS: vizor.cash




@rakka_sol @0xSrMessi @jon_charb This was my original thesis for omfg - omnipair to existing borrow lends ~= unideap to radar relay

