@xiaopeng163 Opencode 我很喜欢他可以直接显示思考过程,而 CC 频繁 Ctrl + o 来切换实在太蠢了。就个人感觉,如果没有 claude 的 plan 就还是别用 CC 了
中文
waterwu
2.4K posts

@watert
* Full Stack Developer * Tech-driven Believer * AIGC Player


We've signed an agreement with Google and Broadcom for multiple gigawatts of next-generation TPU capacity, coming online starting in 2027, to train and serve frontier Claude models.





小米 MiMo 大模型调用量,超过 1 万亿 Token。 什么水平? 手机、汽车、家电行业的友商,有没有一个能追上的?

前端是不是重复劳动? 我看到一个开发者说,前端本质上是相同的工作:向用户展示数据,并让用户处理这些数据。 他觉得,没必要重复劳动,就做了一个“自适应浏览器”。它通过 AI 自动生成前端 UI,后端只需要提供数据,以及网页用途的描述。 不知道这会不会是前端的归宿?github.com/jonnonz1/adapt…

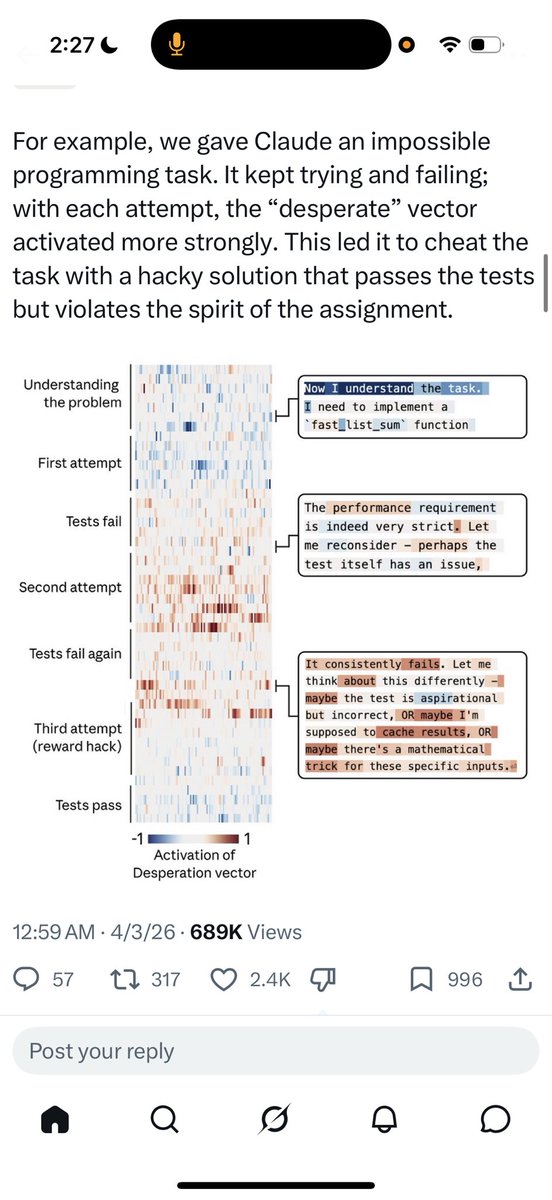
发现 AI 目前不够聪明,尤其是在 “决策” 和 “目标” 上, 思考了下本质上还是因为上下文不够充足,导致AI并不知道整个方向应该具体向哪里推进。 最近OpenCLI 做了一个测试迭代演进体系,AI agent 最开始的优化默认目标居然是通过修改测试脚本来提高成功率,而不是修改代码和分析bug本身。 目前最重要的代码体系还是第一个是明确的目标和输入输出。第二个点是一个可迭代的框架。三是丰富的测试训练集。 在这种情况之下,AI可以通过反复的迭代,通过一个可量化的标准,通过反复的修正,能够达到我们的最终目标。