Minjia Zhang@_Minjia_Zhang_
📢 Yesterday at USENIX ATC 2025, Xinyu Lian from UIUC SSAIL Lab presented our paper on Universal Checkpointing (UCP). UCP is a new distributed checkpointing system designed for today's large-scale DNN training, where models often use complex forms of parallelism, including data, tensor, pipeline, and expert parallelism.
Existing checkpointing systems struggle in this setting because they are tightly coupled to specific training strategies (e.g., ZeRO-style data parallelism or 3D model parallelism), which break down when the training configs need to dynamically reconfigure over time. This makes it difficult to have resilient and fault-tolerant training.
UCP solves this by decoupling distributed checkpointing from parallelism strategies. Our design introduces a unified checkpoint abstraction -- atomic checkpoint, and a full pattern matching-based transformation pipeline, which enables scalable and low-overhead checkpointing with reconfigurable parallelism across arbitrary model sharding strategies.
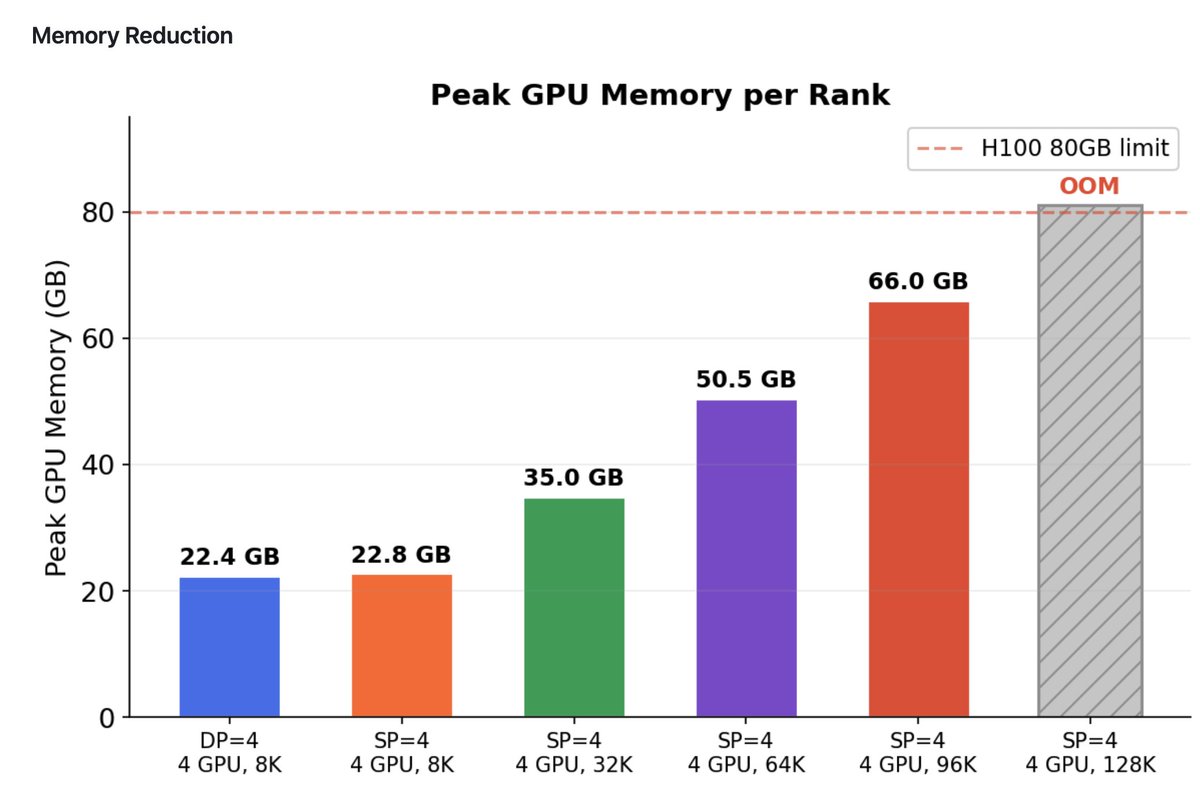
We show that UCP supports state-of-the-art models trained with hybrid 3D/4D parallelism (ZeRO, TP, PP, SP) while incurring less than 0.001% overhead of the total training time.
UCP is fully open-sourced in DeepSpeed. It has been adopted by Microsoft, BigScience, UC Berkeley and others for large-scale model pre-training and fine-tuning, including Phi-3.5-MoE (42B), BLOOM (176B), and many more. It also has been selected for presentation at PyTorch Day 2025 and FMS 2025(the Future of Memory and Storage).
Big thanks to the amazing collaborators from Microsoft and Snowflake: @samadejacobs , @LevKurilenko, @MasahiroTanaka, @StasBekman , and @TunjiRuwase.
🔗 Project: lnkd.in/gG6j4vJe
📄 Paper: lnkd.in/gUiC5kcR
💻 Code: lnkd.in/g6uS29nH
📚 Tutorial: lnkd.in/gi_zWSWh
#ATC2025 #LLM #Checkpointing #SystemsForML #DeepLearning #DistributedTraining #UIUC #DeepSpeed