
Brian
23 posts

Try Kos-1 Lite here: kos.llmdata.com
Read the full blog: llmdata.com/blog/kos-1
English
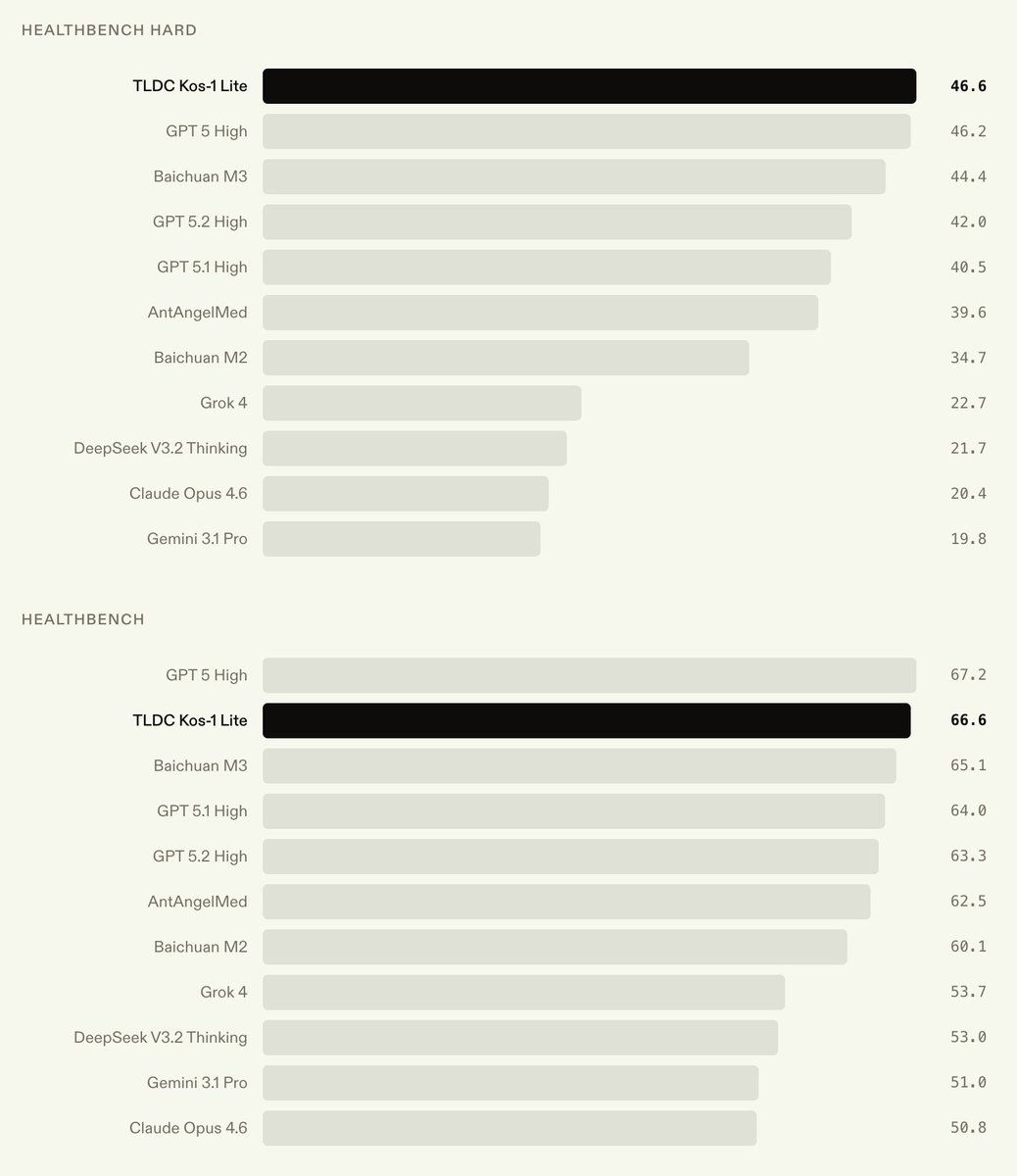
We’re announcing Kos-1 Lite, a medical model that achieves SOTA on HealthBench Hard at 46.6%.
As a medium sized language model (~100B), it achieves these results at a fraction of the serving cost of frontier trillion-parameter models.
English

🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
arxiv.org/abs/2602.23349
A bunch of cool ideas make this possible: [1/n]

English

3. distilling R1 into small models beat large-scale RL on reasoning
4. increasing MoE sparsity yields perf improvements for fixed FLOPs (e.g: 8/384 in Kimi K2)
5. during R1-Zero's pure RL, reflective words like 'wait' spiked 5-7x
would love feedback, especially corrections! :)
English
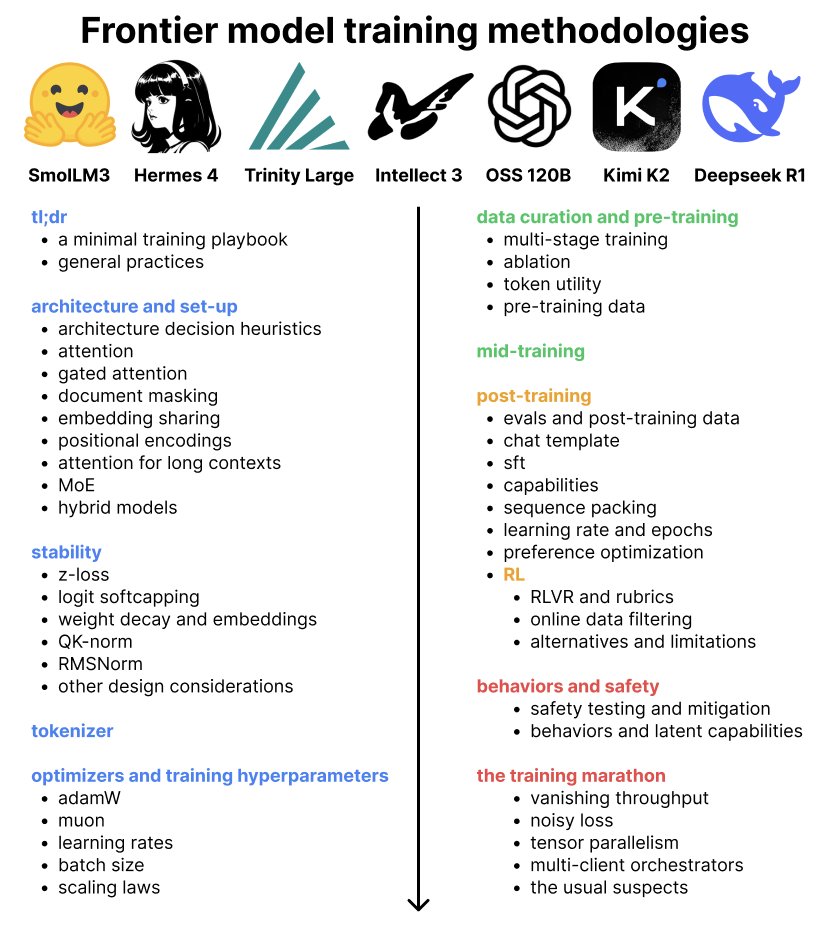
new blog! What methodologies do labs use to train frontier models?
The blog distills 7 open-weight model reports from frontier labs, covering architecture, stability, optimizers, data curation, pre/mid/post-training + RL, and behaviors/safety
djdumpling.github.io/2026/01/31/fro…
English

I forked Codex and added in RLM support.
git clone github.com/halfprice06/co…
cd codex
cd codex-rs
cargo build -p codex-cli
./target/debug/codex
it works! you can use it with your pro sub.
@OpenAIDevs when RLM?
github.com/halfprice06/co…
English

🚀 LightOnOCR-2-1B 🦉 is out, a major update to LightOnOCR.
1B parameters, end-to-end multilingual OCR, and it beats models 9× larger on OlmOCR-Bench while being much faster.
PDF/page in, clean ordered Markdown out, with optional image localization (bbox variants).

English

Much like our RLM-on-KG PageIndex marks a shift toward agent-like, reasoning-first retrieval on graphs, treating structure as the primary signal.
PageIndex feels like a document-centric analog to what RLM-on-KG does for knowledge graphs.
The concept is very similar.
Avi Chawla@_avichawla
Researchers built a new RAG approach that: - does not need a vector DB. - does not embed data. - involves no chunking. - performs no similarity search. And it hit 98.7% accuracy on a financial benchmark (SOTA). Here's the core problem with RAG that this new approach solves: Traditional RAG chunks documents, embeds them into vectors, and retrieves based on semantic similarity. But similarity ≠ relevance. When you ask "What were the debt trends in 2023?", a vector search returns chunks that look similar. But the actual answer might be buried in some Appendix, referenced on some page, in a section that shares zero semantic overlap with your query. Traditional RAG would likely never find it. PageIndex (open-source) solves this. Instead of chunking and embedding, PageIndex builds a hierarchical tree structure from your documents, like an intelligent table of contents. Then it uses reasoning to traverse that tree. For instance, the model doesn't ask: "What text looks similar to this query?" Instead, it asks: "Based on this document's structure, where would a human expert look for this answer?" That's a fundamentally different approach with: - No arbitrary chunking that breaks context. - No vector DB infrastructure to maintain. - Traceable retrieval to see exactly why it chose a specific section. - The ability to see in-document references ("see Table 5.3") the way a human would. But here's the deeper issue that it solves. Vector search treats every query as independent. But documents have structure and logic, like sections that reference other sections and context that builds across pages. PageIndex respects that structure instead of flattening it into embeddings. Do note that this approach may not make sense in every use case since traditional vector search is still fast, simple, and works well for many applications. But for professional documents that require domain expertise and multi-step reasoning, this tree-based, reasoning-first approach shines. For instance, PageIndex achieved 98.7% accuracy on FinanceBench, significantly outperforming traditional vector-based RAG systems on complex financial document analysis. Everything is fully open-source, so you can see the full implementation in GitHub and try it yourself. I have shared the GitHub repo in the replies!
English
English

Arc bioinformatics scientists @noamteyssier and @a_dobin have just released cyto, an ultra-high throughput processor specifically optimized for @10xGenomics Flex single-cell data.
We are excited to make this resource open source: biorxiv.org/content/10.648…

English

Check out our latest research at @Apple !
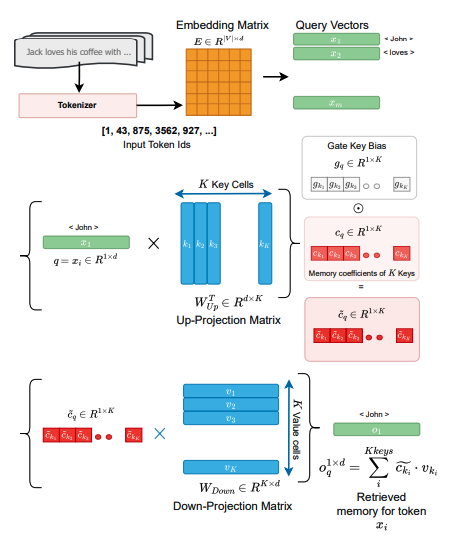
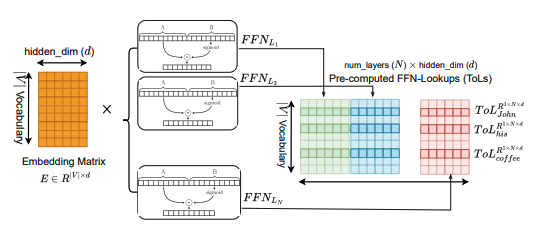
We re-think Transformer FFNs as token-wise neural retrieval memory by decoupling FFNs from self-attention!
- We train FFNs in isolation to learn context-free token lookups (ToLs). It enabled precompute + cache and hot-swap between VRAM and cheaper storage for better efficiency.
- We probe FFNs as memory: we analyze how different tasks route tokens to specific “memory locations” (and how those patterns change across layers / inputs).
- We introduce Flex-MemoryLLM, a flexible variant that recovers most of the accuracy while keeping the memory-style efficiency benefits, narrowing the gap to standard Transformers.
By decoupling FFNs from self-attention we can turn them into context-free, token-wise retrieval memory, we can inspect them and even swap them in and out.
Please check it out here: arxiv.org/abs/2602.00398
With @ajayjaiswal1994, Lauren Hannah, Han-Byul Kim, Duc Hoang, @arnavk1993, @thyeros
#LLM #Transformers #Memory #Interpretability #Efficiency

Ajay Jaiswal@ajayjaiswal1994
What if FFNs were actually human-interpretable, token-indexed memory? Paper Link: arxiv.org/abs/2602.00398 #LLMs #Transformers #Interpretability #Memory #EfficientAI
English
Brian ری ٹویٹ کیا

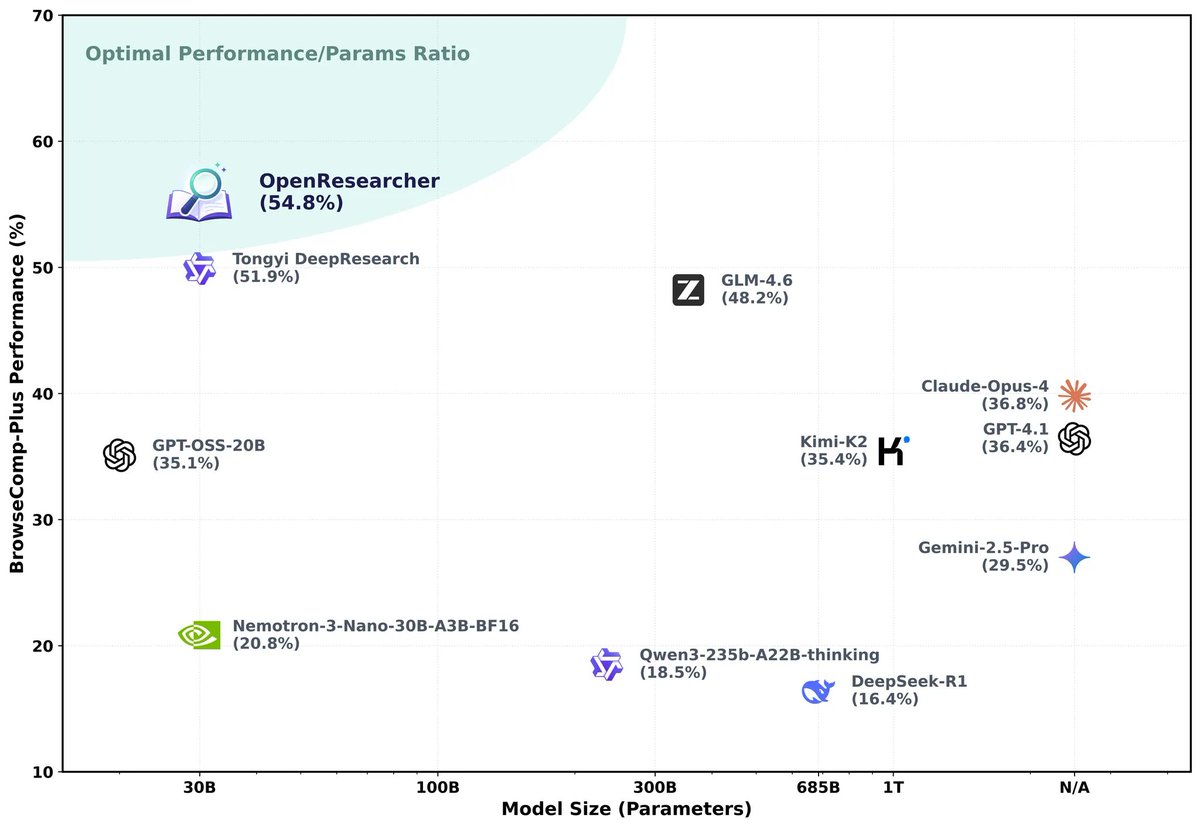
🚀 Introducing OpenResearcher: a fully offline pipeline for synthesizing 100+ turn deep-research trajectories—no search/scrape APIs, no rate limits, no nondeterminism.
💡 We use GPT-OSS-120B + a local retriever + a 10T-token corpus to generate long-horizon tool-use traces (search → open → find) that look like real browsing, but are free + reproducible.
📈 The payoff: SFT on these trajectories turns Nemotron-3-Nano-30B-A3B from 20.8% → 54.8% accuracy on BrowseComp-Plus (+34.0).
🧩 What makes it work?
🔎 Offline corpus = 15M FineWeb docs + 10K “gold” passages (bootstrapped once)
🧰 Explicit browsing primitives = better evidence-finding than “retrieve-and-read”
🎯 Reject sampling = keep only successful long-horizon traces
🧵 And we’re releasing everything:
✅ code + search engine + corpus recipe
✅ 96K-ish trajectories + eval logs
✅ trained models + live demo
👨💻 GitHub: github.com/TIGER-AI-Lab/O…
🤗 Models & data: huggingface.co/collections/TI…
🚀 Demo: huggingface.co/spaces/OpenRes…
🔎 Eval logs: huggingface.co/datasets/OpenR…
#llms #agentic #deepresearch #tooluse #opensource #retrieval #SFT
English

My timeline is all RLM discourse now and I’m here for it.
I also wrote up a super simple example of applying RLMs + DSPy to perform a security review of a codebase.
While it’s only 50 lines of code there’s a lot packed in here.
- Construct a mapping of filename -> content (represented as a dict)
- Define the Signature. In this case a simple dict in, str (markdown) out. There’s a lot we could do here, such as ask for specific vulnerabilities, code line citations, etc.
- set the max iterations to 35; this is an arbitrary number that likely grows with the size of the target codebase
From there the RLM will iterate through the content dictionary, recursively calling sub-LLMs to perform an analysis.
Doing this with any other approach requires writing an entire harness to properly dissect the codebase, manage context lengths and state, etc. The RLM advantage shines here because the model is the one doing all that itself - that’s the point of RLMs. This would work, in theory, against an arbitrarily long and complex codebase (given enough memory to store it, or you get creative with JIT loading).
There’s a ton of low hanging fruit here, and this is an intentionally simplistic example, but should show how easy it is to get started.
Credit to @lateinteraction , @a1zhang & team for what’s surely going to serve as a foundational approach going forward.
English

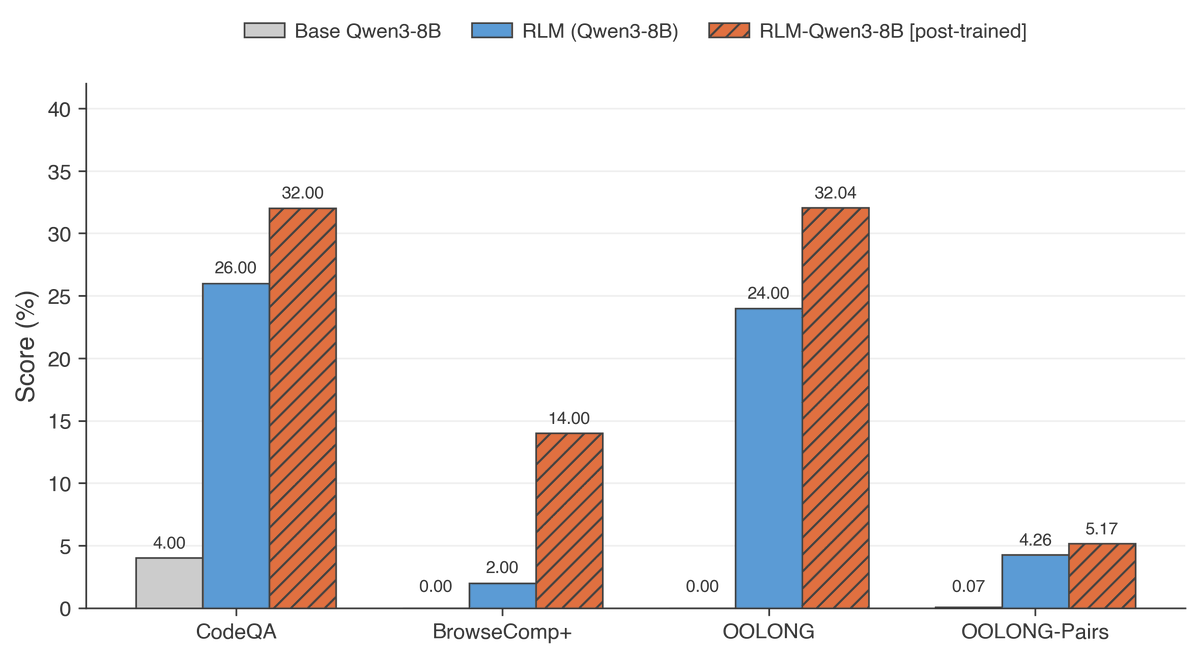
We just updated the RLM paper with some new stuff.
First, we just released RLM-Qwen3-8B, the first natively recursive language model (at tiny scale!).
We post-trained Qwen3-8B using only ~1000 RLM trajectories from unrelated domains to our evaluation benchmarks.
RLM-Qwen3-8B works well across several tasks and delivers a pretty large boost over using an RLM scaffold with the underlying Qwen3-8B model off-the-shelf, and even larger gains over directly using Qwen3-8B directly for long-context problems.
English

Here is a Google NeurIPS paper on how to improve LLM results at virtually no cost:
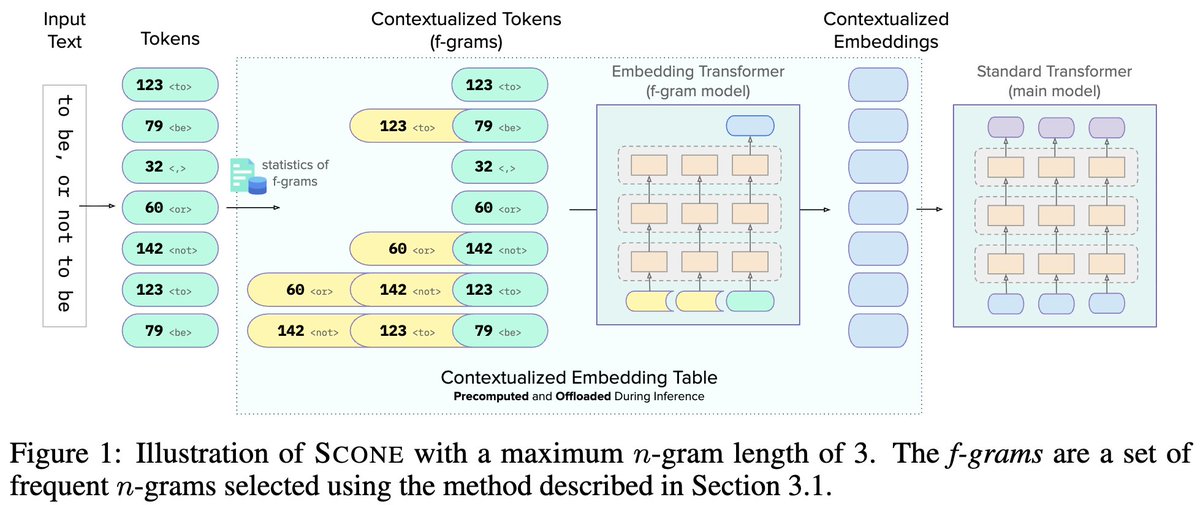
Scaling Embedding Layers in Language Models
Normal LLMs have a fixed vocabulary, usually around 200k tokens, and each token has its own embedding. [1/N]
English

It's crazy how far LLM training has come in just 6 years. Reading more into what they tried with nanochat.
1. 𝗥𝗼𝘁𝗮𝗿𝘆 𝗣𝗼𝘀𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀 (𝗥𝗼𝗣𝗘) - this is a no-brainer since pretty much everyone is universally use RoPE nowadays.
2. 𝗥𝗠𝗦𝗡𝗼𝗿𝗺 with zero learnable parameters to stabilize attention without softcapping weights.
3. 𝗚𝗘𝗟𝗨 𝗶𝘀 𝗿𝗲𝗽𝗹𝗮𝗰𝗲𝗱 𝗯𝘆 𝗥𝗲𝗟𝗨-sq (F.relu(x).square()) for computation sparsity
4. 𝗦𝗦𝗦𝗟 𝗦𝗹𝗶𝗱𝗶𝗻𝗴 𝗪𝗶𝗻𝗱𝗼𝘄 𝗔𝘁𝘁𝗲𝗻𝘁𝗶𝗼𝗻: three short-window layers (1024 context) followed by one long-window layer (2048 context), implemented natively via Flash Attention 3.
Flash attention itself must have sped up GPT-2 training by a huge margin.
5. 𝗚𝗮𝘁𝗲𝗱 𝗩𝗮𝗹𝘂𝗲 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀: are added to the V tensor at alternating layers; this increases capacity (adding ~150M parameters) with almost zero impact on FLOPs.
6. 𝗟𝗲𝗮𝗿𝗻𝗮𝗯𝗹𝗲 𝗥𝗲𝘀𝗶𝗱𝘂𝗮𝗹 𝗦𝗰𝗮𝗹𝗮𝗿𝘀: Karpathy claimed that this simple addition consistently improved performance by 0.003–0.01 bits per byte.
7. 𝗦𝗽𝗹𝗶𝘁 𝗠𝘂𝗼𝗻/𝗔𝗱𝗮𝗺𝗪 𝗢𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻: ICYMI, Muon has been talk of town for the "Adam/AdamW-killer". Not a surprise they tried this
github.com/karpathy/nanoc…
AVB@neural_avb
Bro how can 2 screenshots carry THIS much knowledge Do yourself a favor and read the full github post Dr Karpathy made last night. Things they did to train nanochat. 🙏🏼
English

@cyberandy Very neat. Reading through the docs, it looks like tree generation is going to be a crucial task, and I wonder how expensive this will be computationally? The vid is a little deceptive in that the doc used had already been parsed by their API, so we didn't get to see any latency.
English

Finding myself going back to RSS/Atom feeds a lot more recently. There's a lot more higher quality longform and a lot less slop intended to provoke. Any product that happens to look a bit different today but that has fundamentally the same incentive structures will eventually converge to the same black hole at the center of gravity well.
We should bring back RSS - it's open, pervasive, hackable.
Download a client, e.g. NetNewsWire (or vibe code one)
Cold start: example of getting off the ground, here is a list of 92 RSS feeds of blogs that were most popular on HN in 2025:
gist.github.com/emschwartz/e6d…
Works great and you will lose a lot fewer brain cells.
I don't know, something has to change.
English

@EthanLipnik 👋 Early versions of Claude Code used RAG + a local vector db, but we found pretty quickly that agentic search generally works better. It is also simpler and doesn’t have the same issues around security, privacy, staleness, and reliability.
English

Does anyone know why Codex and Claude doesn't use cloud-based embeddings like Cursor to quickly search through the codebase?
English
nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node).
GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train a model to GPT-2 capability but for much cheaper, with the benefit of ~7 years of progress. In particular, I suspected it should be possible today to train one for <<$100.
Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc.
As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year. I think this is likely an underestimate because I am still finding more improvements relatively regularly and I have a backlog of more ideas to try.
A longer post with a lot of the detail of the optimizations involved and pointers on how to reproduce are here:
github.com/karpathy/nanoc…
Inspired by modded-nanogpt, I also created a leaderboard for "time to GPT-2", where this first "Jan29" model is entry #1 at 3.04 hours. It will be fun to iterate on this further and I welcome help! My hope is that nanochat can grow to become a very nice/clean and tuned experimental LLM harness for prototyping ideas, for having fun, and ofc for learning.
The biggest improvements of things that worked out of the box and simply produced gains right away were 1) Flash Attention 3 kernels (faster, and allows window_size kwarg to get alternating attention patterns), Muon optimizer (I tried for ~1 day to delete it and only use AdamW and I couldn't), residual pathways and skip connections gated by learnable scalars, and value embeddings. There were many other smaller things that stack up.
Image: semi-related eye candy of deriving the scaling laws for the current nanochat model miniseries, pretty and satisfying!
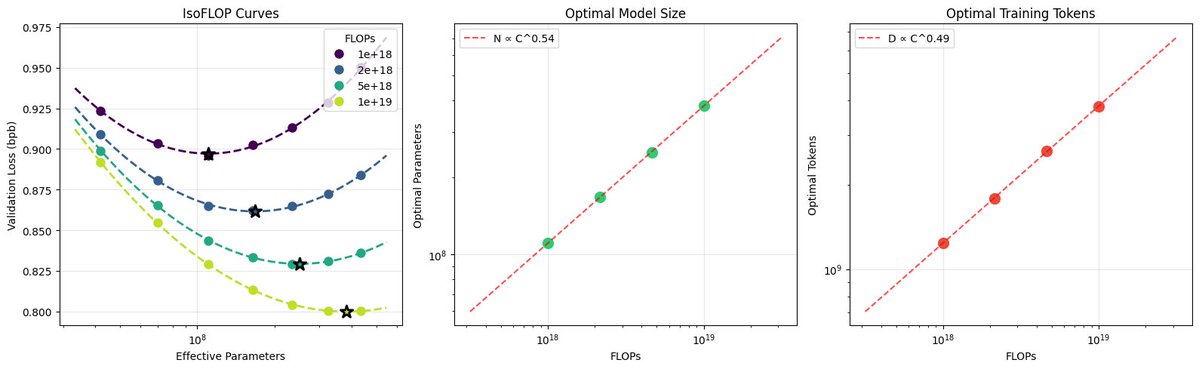
English

It's been a while since I did an LLM architecture post. Just stumbled upon the Arcee AI Trinity Large release + technical report released yesterday and couldn't resist:
- 400B param MoE (13B active params)
- Base model performance similar to GLM 4.5 base
- Alternating local:global (sliding window) attention layers in 3:1 ratio like Olmo 3
- QK-Norm (e.g. popular since Olmo 2) and NoPE (e.g., SMolLM3)
- Gated attention like Qwen3-Next
- Sandwich RMSNorm (kind of like Gemma 3 but depth-scaled)
- DeepSeek-like MoE with lots of small experts, but made it coarser as that helps with inference throughput (something we have also seen in Mistral 3 Large when they adopted the DeepSeek V3 architecture)
Added a slightly longer write-up to my The Big Architecture Comparison article: magazine.sebastianraschka.com/i/168650848/20…

English

We've identified a novel class of biomarkers for Alzheimer's detection - using interpretability - with @PrimaMente.
How we did it, and how interpretability can power scientific discovery in the age of digital biology: (1/6)
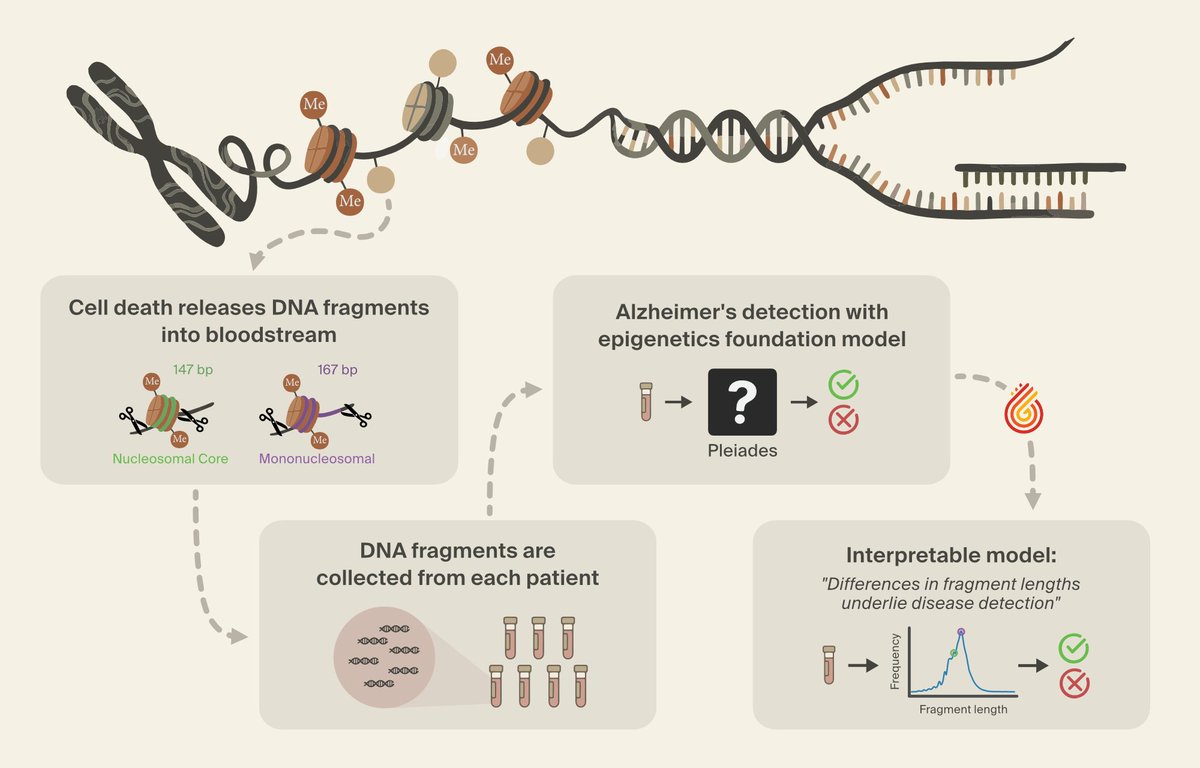
English