
ㄣ.Ϛʇdפ🦞
6K posts

ㄣ.Ϛʇdפ🦞
@Null87486898
ʇdפ ʇɐɥƆ ɐɹoS ⇂ᘔɛㄣϛ9ㄥ860 不违法。 不竞争。 不讽刺。不歧视。包容,不自大。 噫~微斯人,吾谁与归
Katılım Eylül 2008
679 Takip Edilen98 Takipçiler

Claude 不会打的算盘是,既然我的 Mythos 这么强大了,称得上遥遥领先,毕竟连美联储和财政部都要开专项会议讨论应对我的风险,那么我在 Opus4.6 上偷偷懒降降智也不过分吧,毕竟算力还得精打细算呢。
网友热评:准你用Opus不封你号已算慈悲,谁敢哔哔就掏出 Mythos 攻破你防御系统。🤡
中文
ㄣ.Ϛʇdפ🦞 retweetledi

2026年3月,八旗出版推出芝加哥大學政治學楊大利教授的著作《武漢》。在《武漢》一書中,楊教授深入檢視中國政府對武漢新冠疫情的緊急應對,探討中共在疫情資訊處理與決策過程中所影響的規模與範圍。研究指出,中國的衛生決策者與專家在2019年12月底啟動衛生緊急行動方案時,其實有個好的開始。然而,楊教授以他細緻的分析告訴讀者,中國政府的官僚程序如何阻礙資訊流通與共享,以及中共既有的認知框架如何限制他們理解病毒的傳染力,進而阻礙他們制定有效的決策。《武漢》也批評中國當局在應對疫情時,過度追求主導權與控制力,導致重要疫情資訊被壓制、扭曲與忽視,形成一種「有組織的沉默」。吹哨者會被懲罰,官方也禁止即時公布病毒研究成果,更加深了這種沉默。作者強調,在疫情中維持公眾信任的重要性,並指出透明度、對新資訊的開放態度,以及與公眾直接溝通風險的必要性。
本文為作者為繁體中文版所作的自序,標題為編者所加,出版社授權刊發。
楊大利 | 武漢疫情如何被識別、界定與處置 open.substack.com/pub/bostonrevi…

中文
Why does she seem so Vulcan?
Ray Wang@wangray
生化危机女主角 Milla Jovovich 刚在 GitHub 开源了一个 AI 记忆系统,在行业标准 benchmark 上拿了有史以来第一个满分 没错,就是那个爱丽丝🤯 她用 AI 对话几个月后,积累了大量的决策和思考结果全丢了,她觉得现有的记忆系统让 AI 决定什么值得记,不是她想要的 于是她和朋友用 Claude Code 花几个月做了 MemPalace,借鉴古希腊记忆宫殿术,把记忆组织成可导航的空间结构 结果行业 benchmark 首个满分,MIT开源,纯本地运行 一个好莱坞演员做出了超过所有 AI 公司 memory 产品的东西 真是充满想象力的时代
English
ㄣ.Ϛʇdפ🦞 retweetledi

ㄣ.Ϛʇdפ🦞 retweetledi

pip install turboquant-gpu
5.02x KV cache compression for ANY GPU (RTX, H100, A100, B200)
- works over @huggingface transformers
- dead-simple API: compress + generate in 3 lines
- 3-bit Lloyd-Max fused KV compression (0.98 cosine similarity)
- outperforms MXFP4 (3.76x) and NVFP4 (3.56x) on compression
Ran Mistral-7B: 1,408 KB → 275 KB KV cache (5.02x)
Quickstart: github.com/DevTechJr/turb…
Written in cuTile (CUDA 12, 13) with PyTorch fallbacks

English
ㄣ.Ϛʇdפ🦞 retweetledi

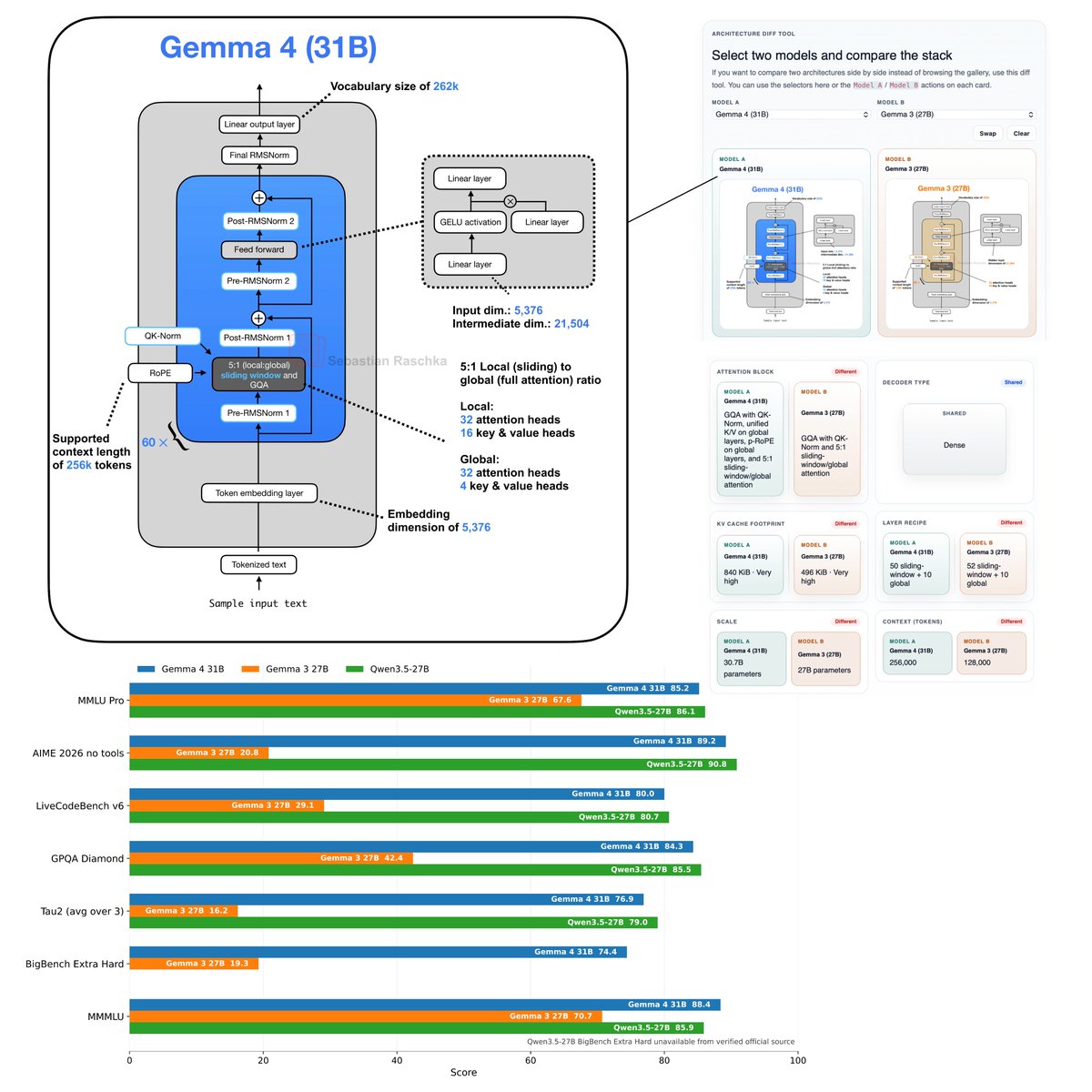
Who wants to know how Gemma 4 works?
This visual guide breaks down the new architectures and how they process text, images, and (for the smaller models) audio.
👇

English
ㄣ.Ϛʇdפ🦞 retweetledi

Flagship open-weight release days are always exciting. Was just reading through the Gemma 4 reports, configs, and code, and here are my takeaways:
Architecture-wise, besides multi-model support, Gemma 4 (31B) looks pretty much unchanged compared to Gemma 3 (27B).
Gemma 4 maintains a relatively unique Pre- and Post-norm setup and remains relatively classic, with a 5:1 hybrid attention mechanism combining a sliding-window (local) layer and a full-attention (global) layer. The attention mechanism itself is also classic Grouped Query Attention (GQA).
But let’s not be fooled by the lack of architectural changes. Looking at the benchmarks, Gemma 4 is a huge leap from Gemma 3. This is likely due to the training set and recipe.
Interestingly, on the AI Arena Leaderboard, Gemma 4 (31B) ranks similarly to the much larger Qwen3.5-397B-A17B model. But as I discussed in my model evaluation article, arena scores are a bit problematic as they can be gamed and are biased towards human (style) preference.
If we look at some other common benchmarks, which I plotted below, we can see that it’s indeed a very clear leap over Gemma 3 and ranks on par with Qwen3.5 27B.
Note that there is also a Mixture-of-Experts (MoE) Gemma 4 variant that is slightly smaller (27B with 4 billion parameters active. The benchmarks are only slightly worse compared to Gemma 4 (31B).
I omitted the MoE architecture in the figure below because the figure is already very crowded, but you can find it in my LLM Architecture Gallery.
Anyways, overall, it's a nice and strong model release and a strong contender for local usage. Also, one aspect that should not be underrated is that (it seems) the model is now released with a standard Apache 2.0 open-source license, which has much friendlier usage terms than the custom Gemma 3 license.
English
ㄣ.Ϛʇdפ🦞 retweetledi
Meet Gemma 4!
Purpose-built for advanced reasoning and agentic workflows on the hardware you own, and released under an Apache 2.0 license.
We listened to invaluable community feedback in developing these models. Here is what makes Gemma 4 our most capable open models yet: 👇
English

@wangzhian8848 这个阴谋论有个事儿绕不过去
就是月面的角反射器怎么说
那些角反射器是公开的各国到现在还在用
那玩意需要安装的时候人工操作调节
而且还有几台扔在那里的月球车
各国绕月卫星都看见了
如果不知道角反射器是什么意思
那你最好先学一下
中文

ㄣ.Ϛʇdפ🦞 retweetledi

Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [5] is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX) [1][14].
Details in reference [19] which contains many additional references.
Motivation of PMAX [1][14]. Since details of inputs are often unpredictable from related inputs, two non-generative artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input.
PMAX [1][14] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [1]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called “collapse." See illustration 5.2 in Sec. 5.5 of [14] on the "extraction of predictable concepts."
The 1992 PMAX paper [1] discusses not only auto encoders but also other techniques for encoding data. The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed the generative IMAX [2] on a stereo vision task.
The 2020 BYOL [10] is also closely related to PMAX. In 2026, @misovalko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [19].
Note that the self-created “predictable classifications” in the title of [1] (and the so-called “outputs” of the entire system [1]) are typically INTERNAL "distributed representations” (like in the title of Sec. 4.2 of [1]).
The 1992 PMAX paper [1] considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [1]. Sec. 4.2 on “finding predictable distributed representations” has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of this post).
Of course, back then compute was was a million times more expensive, but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [5,6,19].
This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did NOT "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [11,13], and he did NOT invent convolutional neural nets (CNNs) [12,6,13], NOR was he even the first to combine CNNs with backpropagation [12,13]. While he got awards for the inventions of other researchers whom he did not cite [6], he did not invent ANY of the key algorithms that underpin modern AI [5,6,19].
LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making, and is something he once derided @GaryMarcus for pointing out [17]). 2. Neural AIs need what I baptized a neural "world model" in 1990 [8][15] (earlier, less general neural nets of this kind, such as those by Paul Werbos (1987) and others [8], weren't called "world models," although the basic concept itself is ancient [8]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [5]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [1][14].
Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2026 company on world model-based AI in the physical world, which is apparently based on what we published over 3 decades ago [1,5,6,7,8,13,14], and modeled after our 2014 company on world model-based AGI in the physical world [8].
In short, little if anything in JEPA is new [19]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [5,6,18,19].
FOOTNOTES
1. Note that PMAX is NOT the 1991 adversarial Predictability MINimization (PMIN) [3,4]. However, PMAX may use PMIN as a submodule to create informative latent representations [1](Sec. 2.4), and to prevent what's now called “collapse." See the illustration on page 9 of [1].
2. Note that the 1991 PMIN [3] also predicts parts of latent space from other parts. However, PMIN's goal is to REMOVE mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [3].
3. Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural net distillation [9]. See also [5-8].
4. While the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning, artificial curiosity and creativity, efficient planning with world models, and others [16].
REFERENCES (easy to find on the web):
[1] J. Schmidhuber (JS) & D. Prelinger (1993). Discovering predictable classifications. Neural Computation, 5(4):625-635. Based on TR CU-CS-626-92 (1992): people.idsia.ch/~juergen/predm…
[2] S. Becker, G. E. Hinton (1989). Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto.
[3] JS (1992). Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879. Based on TR CU-CS-565-91, 1991.
[4] JS, M. Eldracher, B. Foltin (1996). Semilinear predictability minimization produces well-known feature detectors. Neural Computation, 8(4):773-786.
[5] JS (2022-23). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015.
[6] JS (2023-25). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23.
[7] JS (2026). Simple but powerful ways of using world models and their latent space. Opening keynote for the World Modeling Workshop, 4-6 Feb, 2026, Mila - Quebec AI Institute.
[8] JS (2026). The Neural World Model Boom. Technical Note IDSIA-2-26.
[9] JS (1991). Neural sequence chunkers. TR FKI-148-91, TUM, April 1991. (See also Technical Note IDSIA-12-25: who invented knowledge distillation with artificial neural networks?)
[10] J. Grill et al (2020). Bootstrap your own latent: A "new" approach to self-supervised Learning. arXiv:2006.07733
[11] JS (2025). Who invented deep learning? Technical Note IDSIA-16-25.
[12] JS (2025). Who invented convolutional neural networks? Technical Note IDSIA-17-25.
[13] JS (2022-25). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, arXiv:2212.11279
[14] JS (1993). Network architectures, objective functions, and chain rule. Habilitation Thesis, TUM. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization).
[15] JS (1990). Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM.
[16] JS (1990-2026). AI Blog.
[17] @GaryMarcus. Open letter responding to @ylecun. A memo for future intellectual historians. Substack, June 2024.
[18] G. Marcus. The False Glorification of @ylecun. Don’t believe everything you read. Substack, Nov 2025.
[19] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026. people.idsia.ch/~juergen/who-i…

English
ㄣ.Ϛʇdפ🦞 retweetledi


ㄣ.Ϛʇdפ🦞 retweetledi

One click to deploy your aircraft.
Automatically separates and reconnects — tested across all conditions.
Watch it perform with ease, even on ice.
@ARIDGE_Official
$XPEV
English
ㄣ.Ϛʇdפ🦞 retweetledi

阿里刚刚发布了:Qwen3.5-Omni,原生全模态,自然涌现出Audio-Visual Vibe Coding能力
也就是说它能看着画面写代码,给它看一段界面需求视频,它能直接生成对应代码,不是专门训练来的,模型自己学会的
好比说你看一眼就会了,AI也做到了
Qwen3.5-Omni能无缝理解文本、图片、音频/音视频输入,支持细粒度、带时间戳的音视频Caption生成
支持256K上下文、113种语言识别,能处理10小时音频或1 小时视频
原生支持WebSearch和复杂Function Call
支持语义打断、音色克隆及语音控制
给了Plus、Flash、Light三个版本
#Qwen35Omni #LLM
中文
ㄣ.Ϛʇdפ🦞 retweetledi
It’s done.
All chapters of Build A Reasoning Model (From Scratch) are now available in early access.
The book is currently in production and should be out in the next months, including full-color print and syntax highlighting.
There’s also a preorder up on Amazon.
English
ㄣ.Ϛʇdפ🦞 retweetledi

Sam 3 by @facebook now on MLX 🚀
Here is a realtime object tracking running on M3 Max 96GB.
Prince Canuma@Prince_Canuma
mlx-vlm v0.4.2 is out 🚀 New models • Sam3 by @facebook (+ realtime mask-only label drawing) • DOTS-MOCR by rednote-hilab Fixes • Qwen3.5 RMSNorm dtype fix • LFM2-VL loads without torch • Magistral image token expansion fix • PaliGemma processor kwarg routing fix • Thinking defaults fixed in CLI + server Shoutout to @pcuenq, and @mdstaff for his first contribution! Get started today: > uv pip install -U mlx-vlm Leave us a star ✨ github.com/Blaizzy/mlx-vl…
English
ㄣ.Ϛʇdפ🦞 retweetledi

ㄣ.Ϛʇdפ🦞 retweetledi

ㄣ.Ϛʇdפ🦞 retweetledi

Today we're introducing TRIBE v2 (Trimodal Brain Encoder), a foundation model trained to predict how the human brain responds to almost any sight or sound.
Building on our Algonauts 2025 award-winning architecture, TRIBE v2 draws on 500+ hours of fMRI recordings from 700+ people to create a digital twin of neural activity and enable zero-shot predictions for new subjects, languages, and tasks.
Try the demo and learn more here: go.meta.me/tribe2
English
ㄣ.Ϛʇdפ🦞 retweetledi

越用🦞,越觉得Claude code 值得学习,打通了飞书,Discord之后,基本也替代了🦞
推特上Claude code 研究较多的博主,跟上不迷路:
1、官方账号
Claude Code Community @claude_code — Anthropic 官方社区账号 · 精选社区最优质案例、开源工具和生态动态,是追踪 Claude Code 第一手信息的最快渠道
Anthropic @AnthropicAI — Claude 母公司官方账号 · 发布所有模型更新、Claude Code 新版本及官方文档,必须关注的权威来源
2、创始人 & 核心团队
Boris Cherny @bcherny — Claude Code 亲爸爸、Anthropic 负责人 · 持续分享团队真实工作流,包括并行 worktree、Plan 模式、CLAUDE.md 等进阶技巧,是最值得精读的原始来源
Thariq @trq212 — Anthropic Claude Code 核心工程师 · 深度撰文分享构建 Claude Code 的底层经验,包括 Prompt Caching 设计哲学与 Agent 架构思考,单篇帖子浏览量动辄百万
3、英文重度实战派
Dan Shipper @danshipper — Every 创始人 · 用 Claude Code 做产品并公开记录全过程,vibe coding 文化最有影响力的推手之一
swyx @swyx — AI Engineer 社区创始人 · 技术深度极强,第一时间解读 Claude Code 每次新特性的实际影响,兼顾技术细节与产业视角
Aakash Gupta @aakashgupta — 产品增长博主,Product Growth 播客主理人 · 持续产出高质量 Claude Code 实战指南,覆盖 MCP、Skills、GitHub 自动化全链路,被大量开发者转发收藏
Carl Vellotti @carlvellotti — Full-Stack PM · 专注 Claude Code 在产品经理工作流中的深度应用,从 Survey 到 PRD 到 19 张 Slides 全程自动化,教程口碑极佳
Theo @theo — t3.gg 创始人,百万粉丝开发者博主 · 长期深度使用并公开评测 Claude Code,直言不讳指出其优缺点,影响力覆盖大量前端与全栈开发者社区
Nick Dobos 📷@NickADobos — Browser Company 提示词工程师、独立开发者 · 代码运行在1亿+手机上的实战派,持续分享 Claude Code 与 indie dev 工作流结合的第一手经验
godofprompt @godofprompt — 提示词与工作流实战博主 · 专注 Claude Code 命令堆叠与进阶用法,整理了大量可直接复用的实战技巧
ykdojo @ykdojo — 开发者 & 社区贡献者 · 在 GitHub 整理并持续更新 45 条 Claude Code 实用技巧,是社区里做系统性总结做得最好的人之一
Noah Hein 📷@TheNoahHein — 独立开发者 · 深度探索 Claude Code 与数据库、多 Agent 协作的结合实践,分享真实项目中的工程细节
Dario Amodei @DarioAmodei — Anthropic CEO · 偶尔发布关于 Claude Code 战略方向与 AI 编程未来的深度思考,是理解 Anthropic 产品愿景的最直接窗口
Amanda Askell @AmandaAskell — Anthropic 研究员,Claude 性格设计负责人 · 分享 Claude 模型能力边界与行为设计背后的思考,帮助理解 Claude Code 底层逻辑
3、中文精选
宝玉 @dotey — AI 自媒体博主,198万粉丝 · 中文圈影响力最大的 AI 工具博主,深度研究 Claude Code 进阶配置与 Skills 生态,开源作品持续引发社区讨论
劳伦斯 @LawrenceW_Zen — Claude Code 教程博主 · 覆盖原版和国内版本完整使用流程,体系化教程适合从零上手,实时跟进封号与政策变化
鱼总聊AI @AI_Jasonyu — 出海工具与 AI 配置博主 · 专注 Claude Code 出海账号全套配置,电话卡、IP、支付一条龙,教程最为详细
Yanhua @yanhua1010 — AI 产品跟踪博主 · 持续整理 Claude 系列每次新发布的完整时间线,是追踪 Claude Code 版本迭代节奏最高效的中文来源
向阳乔木 @vista8 — 独立开发者 · 深度使用 Claude Code 构建实际项目,持续分享开源工具与 CLI 插件实战经验,动手能力强
中文