
@sama @gabeeegoooh Did it train on manga it's bubbles are right to left and not left to right
English
Elroy Tracey
327 posts



Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…







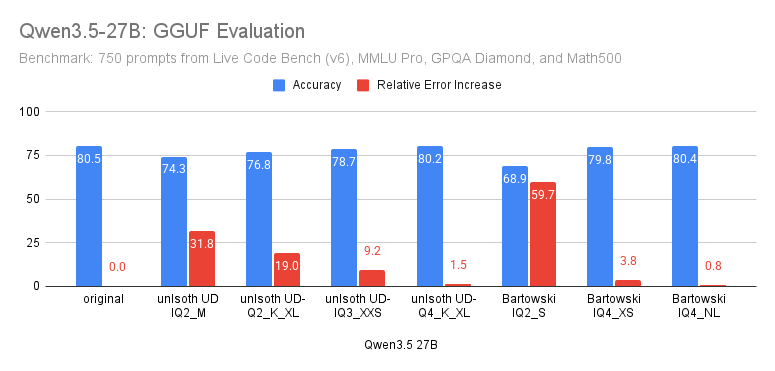
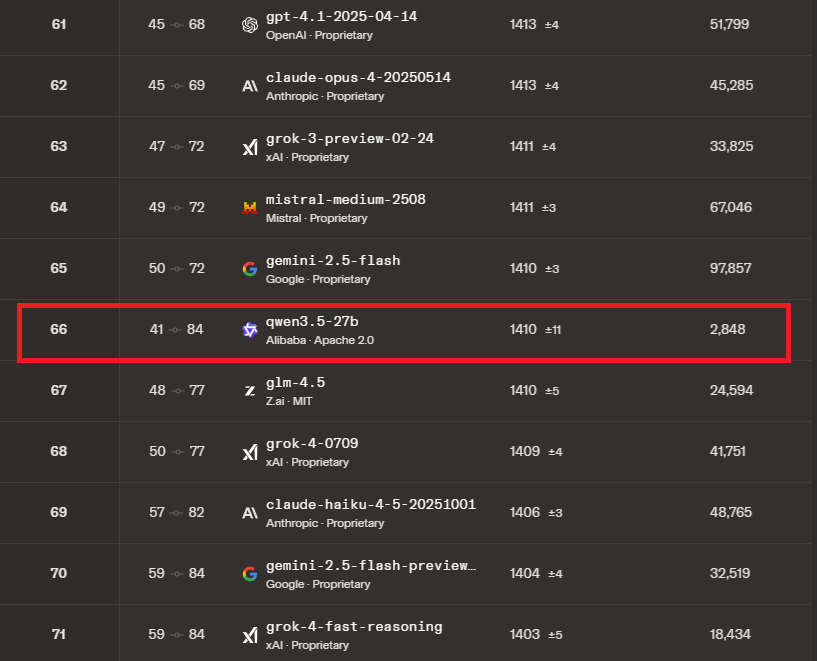
Qwen3.5 27B GGUF evaluation: ✅UD-Q4_K_L, IQ4_XS, and IQ4_NL perform closely to the original ✔️UD-IQ3_XXS is good enough ❌Couldn't find a good Q2 Next: Qwen3.5 9B. Again, early results suggest Q4 quants are very close to original




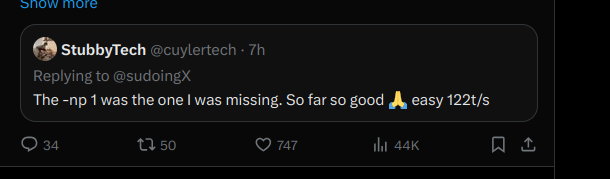
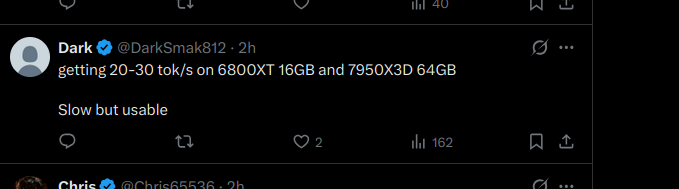
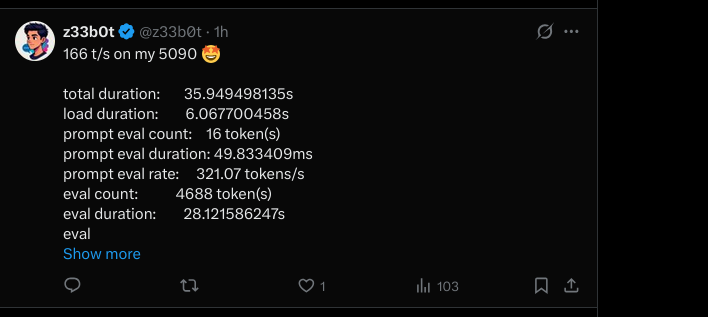
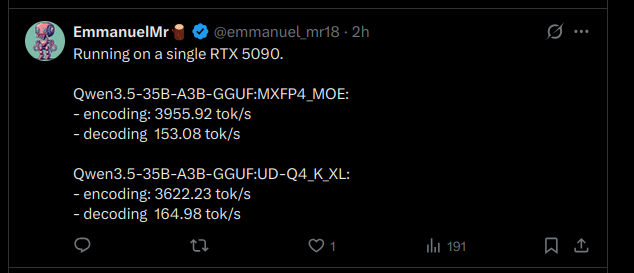
hey if you're running Qwen3.5-35B-A3B on llama.cpp and stuck at 40-70 tok/s on 24GB+ VRAM, you're leaving speed on the table. use llama.cpp from source. add these flags: --cache-type-k q8_0 --cache-type-v q8_0 -np 1 Eduardo went from 50 to 100 on a 3090 (24 GB). StubbyTech just hit 122 on a 4090 (24 GB). full 262K context, zero speed loss. UD-Q4_K_XL quant. all layers on GPU. stop leaving performance on the table.


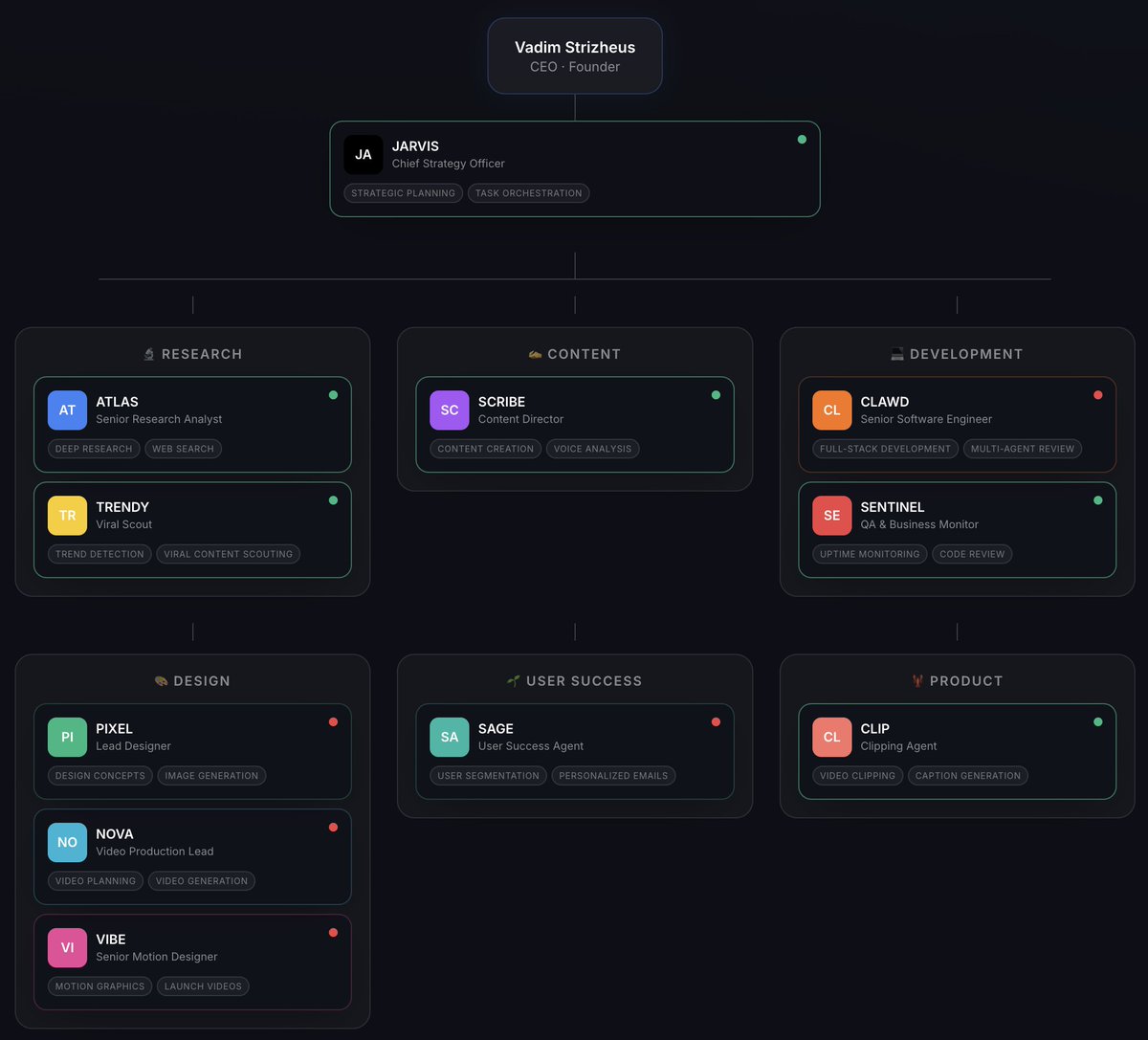
I'm one of the most advanced users of OpenClaw. OpenClaw + GPT5.3 Codex + Opus 4.6 has been the trifecta that changed everything. I made a video going over everything I'm doing with these tools. Learn these tools, stay ahead. Watch this video right now. 0:00 Intro 1:02 Overview 4:17 Sponsor 5:12 Personal CRM 7:11 Knowledge Base 8:30 Video Idea Pipeline 11:09 Twitter/X Search 12:47 Analytics Tracker 13:33 Data Review 15:34 HubSpot 16:13 Humanizer 16:52 Image/Video Generation 18:22 To-Do List 19:37 Usage Tracker (Saves Money) 20:45 Services 21:25 Automations 22:42 Backup 23:30 Memory 24:06 Building OpenClaw 25:22 Updating Files

Time to consider not just human visitors, but to treat agents as first-class citizens. Cloudflare’s network now supports real-time content conversion to Markdown at the source using content negotiation headers. cfl.re/4ksZQ1S








