
Haka Haky
421 posts

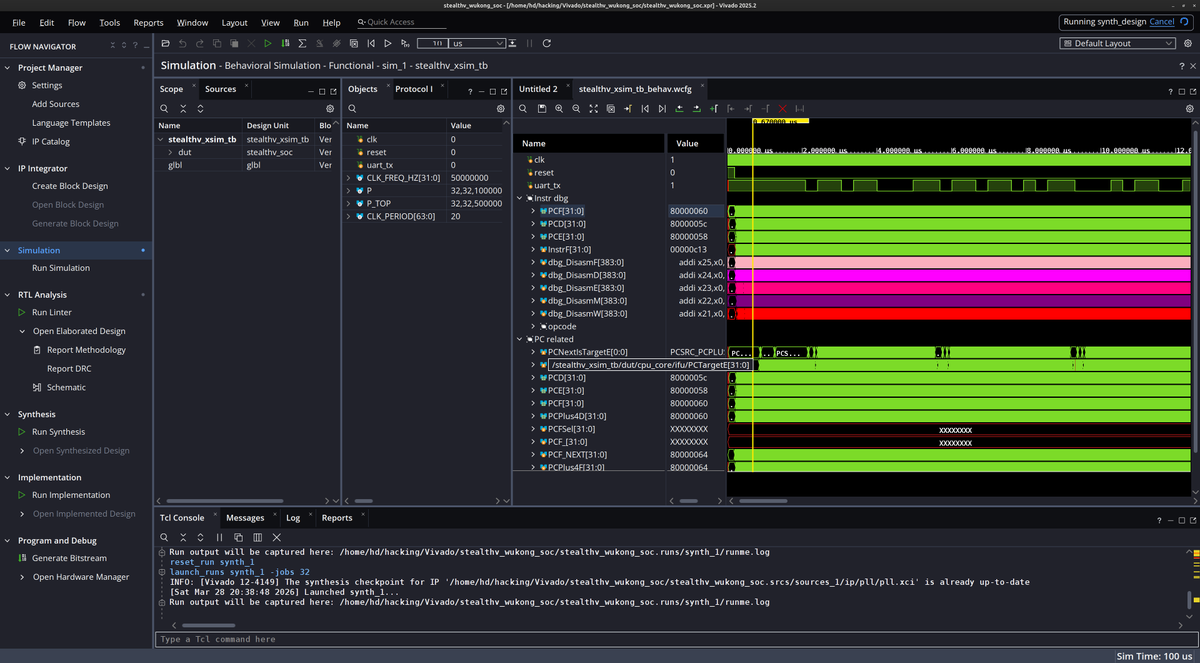
Only UART. No VGA, no framebuffer. Just UART.
Picked up my pipelined CPU Kian StealthV again after not touching it for a year. Just playing around a bit to get back into it and find the motivation to push it towards a Linux SoC.
asic destroyer@splinedrive
@ATaylorFPGA gave me this QMTech Wukong board as a gift. This is the second board I’ve received from him, got it today. The other one is running my KianV Linux SoC and is basically my always-on machine. I’ll use this new one for my next Linux SoC. This one should be fast as hell, though probably not very ASIC-friendly since it needs a lot of resources. It’s going to be a pipelined Linux SoC. The plan is to add an SDRAM burst controller with proper clock domain crossing, so the memory can run at a higher frequency than the core. Later I’ll either build a DDR controller myself. Long term goal is to move on to more advanced CPUs, superscalar and out-of-order. I would probably already be deep into this project if the ASIC work hadn’t gotten in the way, but honestly I’m glad I did those ASICs. That’s my next big project for this year. Thanks Adam, really appreciate it.
English
Haka Haky retweetledi

KiCad Version 10.0.0 Released
The KiCad project is proud to announce the latest major stable version 10 release. See the blog post on the KiCad website for more information about this release.
kicad.org/blog/2026/03/V…
English
Haka Haky retweetledi

Meet the new Stitch, your vibe design partner.
Here are 5 major upgrades to help you create, iterate and collaborate:
🎨 AI-Native Canvas
🧠 Smarter Design Agent
🎙️ Voice
⚡️ Instant Prototypes
📐 Design Systems and DESIGN.md
Rolling out now. Details and product walkthrough video in 🧵
English
Haka Haky retweetledi

@tobi Who knew early singularity could be this fun? :)
I just confirmed that the improvements autoresearch found over the last 2 days of (~650) experiments on depth 12 model transfer well to depth 24 so nanochat is about to get a new leaderboard entry for “time to GPT-2” too. Works 🤷♂️
English
@seti_park @Google Google at Tel Aviv must be a great place to work
English



$MU I worked 21 years as an HBM, DRAM & NAND engineer.
AMA is open. Ask me anything.
I'll drop rare insights where I can.

Trade Whisperer@TradexWhisperer
$MU Bargain of the Century PE Ratio: 15.5 Sales Ratio: 2.33 50% Increase in HBM (AI Memory) Sequentially. DRAM/NAND prices are surging.
English
Haka Haky retweetledi

@GeminiApp Where 3D printing meets AI, possibilities become limitless.
English
Haka Haky retweetledi

LOL
4chan founder m00t is on the Epstein Files.

English

this is trying to solve a problem that's not a problem. in fact, it's essential.
circuits are inherently visual. this is like trying to make the blueprints of a house in code. makes no fucking sense.
the topology of circuits matter and how they are expressed spatially in a schematic matters even more. THIS IS THE INFORMATION. don't get rid of it!!!
not everything benefits from abstraction and syntax.
English


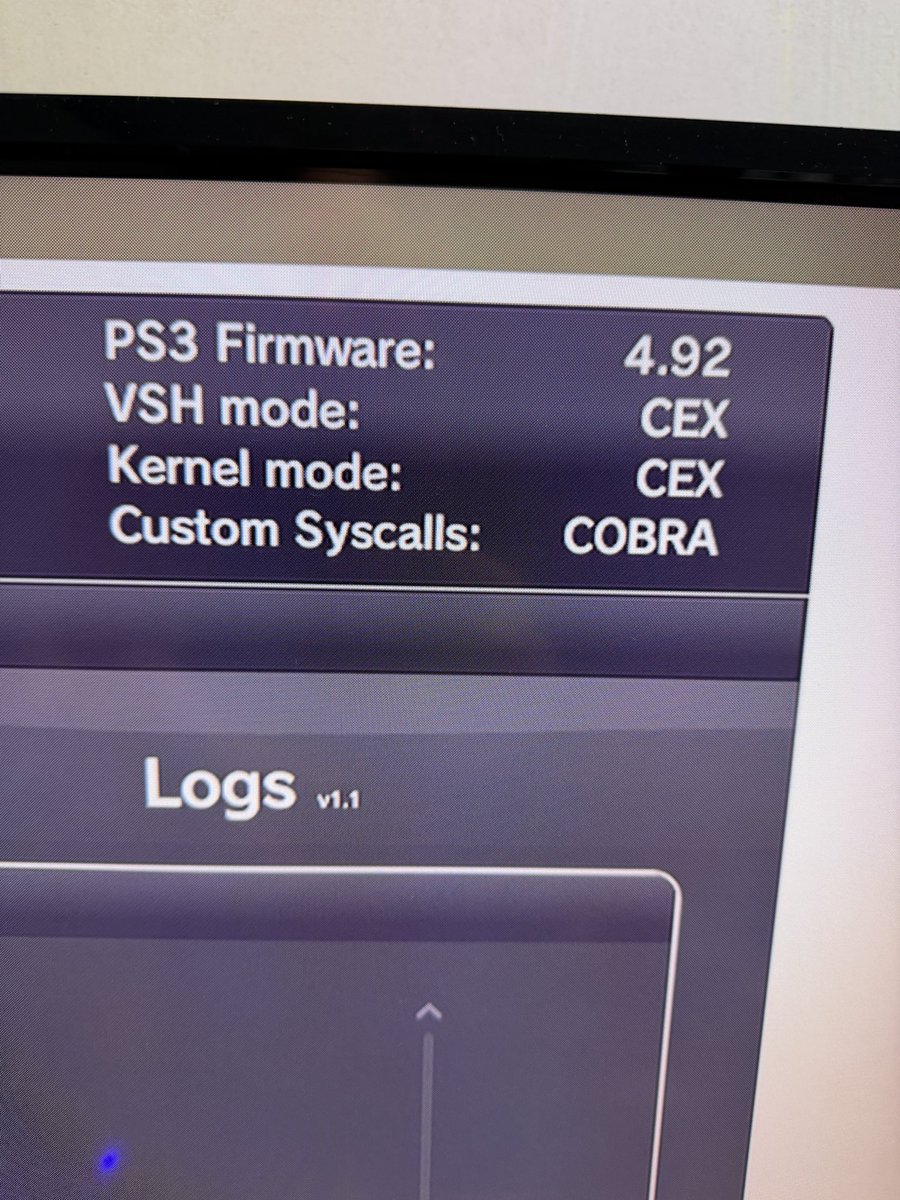
🚨 HISTORY IN THE MAKING for the #PS3 Scene! 🚨
Thanks to the incredible work of the development team, the "impossible" is now reality 🤯
Full working qCFW (BadWDSD) using a Raspberry Pi Pico! 🟢🛠️
This is the ONLY solution that unlocks full qCFW capabilities on these models, and now everyone will be able to use it ❤️🩹
✅ Supported: Super Slim, Slim 3000 & late 2504.
🏆 Likely the first unit in Poland (and one of the few globally) to have this fully operational.
Goodbye HEN, hello full power! 👋
Huge respect to: @aomsin2526 for creating this & team 🤝🏆
#PS3Modding #BadWDSD #PlayStation3 #FreeHomebrew #RetroGaming #Poland
English



@i2cjak yea, but posers don't know about v11 features. my company is working on the 3d_gal. route, place anything in 3d work on the board at 90, at 45, doesnt matter.
GIF
English


Haka Haky retweetledi

🚨 Here is the full 42 minutes of my crew and I exposing Minnesota fraud, this might be my most important work yet. We uncovered over $110,000,000 in ONE day. Like it and share it around like wildfire! Its time to hold these corrupt politicians and fraudsters accountable
We ALL work way too hard and pay too much in taxes for this to be happening, the fraud must be stopped.
English
The tapeout deadline is over, and this evening I started working on the PCB design. I’d always wanted to build an FPGA board with SDRAM, but now I have the time to design a PCB for my own RISC-V Linux SoC ASIC with SDRAM and everything. thanx wafer.space @mithro

asic destroyer@splinedrive
Wild that 50 years later I can, as a one-man show, build an ASIC from scratch that boots Linux and outperforms a PDP-11/83. LMAO. wafer.space #gf180mcu
English

@NgaiBenny Currently it's just my homebrew script, maybe I can turn it into an app?
English


@__tinygrad__ @damageboy @h_gskrd So LPDDR memory and networking (I'd assume very high speed ~ 100 GbE up) in 3000 LoC?
Good luck with the transceivers/PHY? I guess?
English

@damageboy @h_gskrd Ahh, I see. This is an ad for Broadcom.
NoC + LPDDR memory + networking. No PCIe and no HBM.
English

Hahaha,
Never deleting this app...
Where am I going to find this level of entertainment.
3000 lines of Verilog code my ass. Here is just the line count for HBM4 rtl, no test assets included:

the tiny corp@__tinygrad__
The Anthropic TPU deal solidifies it. There's two companies that can make training chips, NVIDIA and Google. Elon tried with Dojo. Amazon tried with Trainium. DeepSeek tried with Huawei. Countless startups are flailing with multiple tapeouts and no real adoption. The funny thing is, the TPU chip itself is very simple. The difference is all the software (XLA-TPU is the best deep learning compiler, too bad it's closed source). In 2 more years, tinygrad will be actually 1.0, with performance exceeding all other libraries. There was a lot of Dunning-Kruger on the way, but we maintain the underlying abstractions required for all deep learning style compute are very simple. At this point, the backend specific code is 1,000 lines. The Verilog for an accelerator should only be about 3,000. We'll build it on FPGAs, and then look for a partner to work with to tape it out. PS: We're still hard at work on the AMD MLPerf contract. AMD has made big strides on their mainline stack in the last 2 years. It's mirroring the NVIDIA stack, but I've come to respect this strategy more and AMD will soon be an uncontested third player in the training space.
English









