
Joe Gibbons
3.5K posts



the reason is marketing!
Patrick OShaughnessy@patrick_oshag
Interesting that in three of my recent conversations with Krishna at Anthropic, @dylan522p, and @GavinSBaker, each said that frontier tokens are capturing the majority of the economic value. Gavin: "An overwhelming amount of the economic returns to AI at the model layer have been at the frontier. That's surprising to me, and I think it's been surprising to a lot of people. This is one of the most important questions to be answered, and you need to have a hypothesis on it as an investor." Krishna: "We think the returns to frontier intelligence are extremely high. Customers invest really heavily in more tokens with the newer models. The ones at the frontier clearly are capturing this economic value, driving meaningful ROI for customers. The returns to frontier intelligence are not slowing down." Dylan: "No one gives a crap about GPT-4 class models. They want the frontier because the frontier lets them create the economically valuable things."
English
Joe Gibbons retweetledi

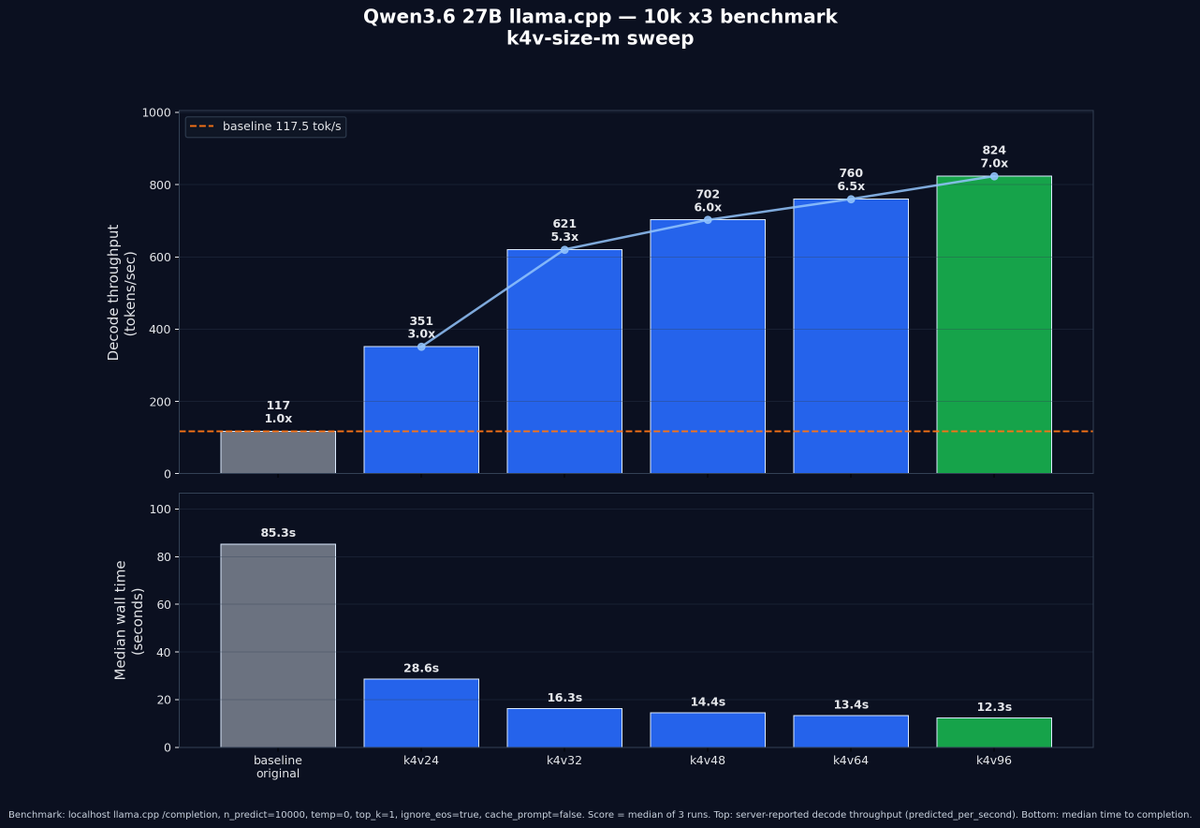
llama.cpp release b9235 added some new toys for boosting inference.
Benchmarked Qwen3.6 27B on an RTX 5090 with llama.cpp, using speculative n-gram tuning across 10k generated tokens tests.
Increasing --spec-ngram-map-k4v-size-m scaled decode throughput (predicted_per_second) up to ~7x faster accepted output token generation.
A follow-up 7x50k token generation tests on k4v64 and k4v96 samples confirmed the sustained 10k-token performance, making k4v96 winner.
k4v128 was tested too, but less stable against k4v96 in the 7x50k token run, so it was removed from the charts.
Real-world results remain anecdotal, albeit k4v96 showed a much lower acceptance rate than traditional --spec-draft-n-max 3 while still producing faster evaluation speeds - so the trade-off seems to be worth it.
Flags in comments below for the k4v96 tested sample.
English
@antigravity That's fantastic but is it trained to be far-left over reality?
English

Introducing Gemini 3.5 Flash ⚡️
Normally, Gemini 3.5 Flash is 4x faster than other models with frontier performance. For a limited time, Antigravity is serving it 12x faster thanks to custom inference tricks, delivering incredible speed for your workflows. 🚀
See the performance in this demo: generating pixel art from photos, orchestrating multi-agent workflows to write and register sprites, and spawning browser subagents to auto-test rendering: 👇
English
@cryptopunk7213 model tuned with model harness in mind, is the key
English

i was completely wrong about cursor
composer 2.5 is an amazing model and i’m convinced the model harness is as important as training.
this bodes well for the cursor + spacexai combo
they’re the only one with a shot at joining the leaders in frontier coding.
wrote some thoughts
Ejaaz@cryptopunk7213
English
@jun_song closing in on a sweet spot of cloud pricing vs locallllm, I'm going for the latter - forgetting the East v West, capitalist v communist politics - the commies are giving me quality models for free! I'll take em, with abliteration!
English

Every AI frontier labs are cutting our usage limit without notice.
Because it’s legal, and inference cost is skyrocketing.
It’s not a surprise.
Get Local LLMs now.
J J@jturntdev
OpenAI have secretly adjusted our limits. Last week before limit reset. I was using Xhigh all day. 5 day straight i couldn’t get my usage below 55% weekly usage. Since Yesterday, I’ve done 40% of my quota, out of nowhere. So whats going on ? @thsottiaux @sama @OpenAIDevs
English
@jun_song @Maciej25956571 very much agree with this, get in now on a 3090 or more if you can afford it. It may be slower and need a lot of prodding but you can keep your job for a long time if you agentic code it/DSPy/script it right, lots of thinking GBNF/templates out there to get thing working better
English
@Maciej25956571 That’s why we should buy before everything skyrockets.
I’m expecting current $200 subs to be $1000 (5x) by the end of year.
English
What makes you think Cloud AI will get cheaper?
(I still get lots of comments from non-followers)
> Grok is training 1.5T model (currently 0.5T)
> Mythos has x3 parameters than Opus
> GPT parameters getting larger
It’s simple math, they need to spend x3 on inference to serve.🧵
English
@LLMJunky X should include List members here, I may not follow you but you're in my "AI" list - just to keep things segmented on my interests
English

Joe Gibbons retweetledi

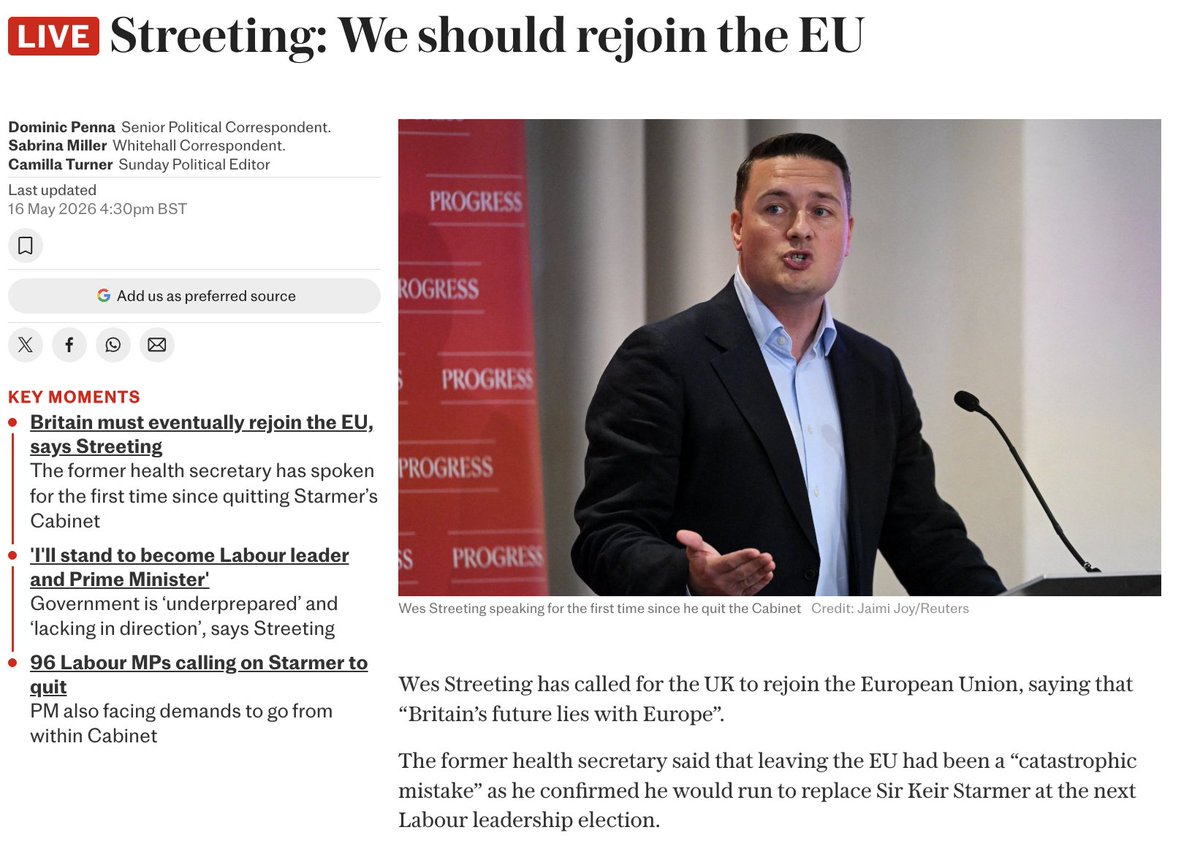
They think they can do what they like without a mandate.
The problem isn't Starmer. It's Labour.
English
Joe Gibbons retweetledi

Joe Gibbons retweetledi

@stevibe Cheers. This is great but a little issue when I have all the Bench Packs installed, the New Tan dialog where you pick one out doesn't show the Open Benchmark button - might simply be my font sizes and there is a workaround to search for the Bench Pack. Great though, thanks.
English

BenchLocal v0.2.5 is out!
> The big one: repeated test runs with majority voting (1, 3, 5, 7, or 9 runs per test).
> Plus error classification, retry actions, per-scenario timings & more.
github.com/stevibe/BenchL…

English
Joe Gibbons retweetledi


@levelsio need a localllm version of this with genuine logs of prompts, 12, 16, 24GB models - it would be fun to see what can be done with a clever harness (prizes aq lot lower in $ though)
English

🏆 The Vibe Jam of 2026 sponsored by @cursor_ai + @boltdotnew + @heyglif + @tripoai is now being judged!
Me and @s13k_ are now judging the ~1000 games of
When either one of us likes a game, it goes on to the next round, so it's like a first stage
@s13k_ built an awesome judging system that lets us just play the games in the browser (most work in an iframe) and then immediately score them
Then in the second round, we send the remaining games to the other judges:
- @timsoret from @oddtalesgames
- @ericzakariasson from @cursor_ai
- @NicolaManzini from VibeSail
- Alessandro from @OverJumpRally
The prizes are:
- First place: $25,000
- Second place: $10,000
- Third place: $5,000
19 games done, 926 to go!

@levelsio@levelsio
And.....✅ DONE! The Vibe Jam of 2026 sponsored by @cursor_ai + @boltdotnew + @heyglif + @tripoai is officially closed 🕹️ 945 games submitted 🛝 242,212 players 👁️ ~12 million views on X Now me and @s13k_ will start the judging process, probably pre-vetting games first with some help from AI (like if the games load at all) and then they go on to all the judges I want to thank everyone who participated! ❤️ There's only 3 cash prizes but even if you don't win, I hope you all had fun creating things, which is the best part of AI for me, it lets me create things I could never have dreamt of making before It's already clear to me from the submissions that AI's ability to help you create beautiful and fun games has progressed a lot, last year's games looked clunky and basic, this year's games are starting to look like stuff you could find on Steam There's no specific deadline for when judging is done but we'll try to be as fast as possible, last year it took 2 weeks I think! THANK YOU!!!
English

When you realize you still need to spend another $4 after spending $6,000 on a MacBook.
will depue@willdepue
Tired of holding your laptop half open to keep your agents running? Introducing AgentPlug: A USB-C dummy plug that keeps your Mac in clamshell mode by pretending to be an external display! No commands, no security worries (just pull it out to stop!), no hassle.
English
@DealsForge @cjzafir I found that too, they're so fast that it's so easy to correct any mistakes. The ELM concept does sound intriguing for a specialized coding model, I hope we get OSS versions of those.
English


If you love fine-tuning open-source models (like me), then listen.
> Start with 1B, 2B, 4B, and 8B models. (Don't start with a 27B model or bigger at first.)
> Use WebGPU providers. I use Google Colab Pro for any model smaller than 9B. A single A100 80GB costs around $0.60/hr, which is cheap. Enough for small models.
> Don’t buy GPUs unless you fine-tune 7 to 10 models. You'll understand the nitty-gritty in the process.
> Use Codex 5.5 × DeepSeek v4 Pro to create datasets. Codex to plan, DeepSeek v4 Pro to generate rows.
> Use Unsloth's instruct models as a base from Hugging Face. Yes, there are others too, but Unsloth also provides fast fine-tuning notebooks.
> Use Unsloth's fine-tuning notebooks as a reference. Paste them into Codex, and Codex will write a custom notebook with the configs you need.
> Spend 1 day learning about:
- SFT (supervised fine-tuning)
- RL training (GRPO, DPO, PPO, etc.)
- LoRA / QLoRA training
- Quantization and types
- Local inference engines (llama.cpp)
- KV cache and prompt cache
> Just get started. Claude, Codex, and ChatGPT can design a step-by-step plan for how you can fine-tune your first AI model.
Future tech is moving toward small 5B to 15B ELMs (Expert Language Models) rather than general 1T LLMs.
So fine-tuning is an important skill that anyone can acquire today.
Tune models, test them, use them. Then fine-tune for companies and make a career out of it. (Companies pay $50k+ to fine-tune models on their data so they can get personalized AI models.)
Shoot your questions below. I'll be sharing in-depth raw findings about this topic in the coming days.
English
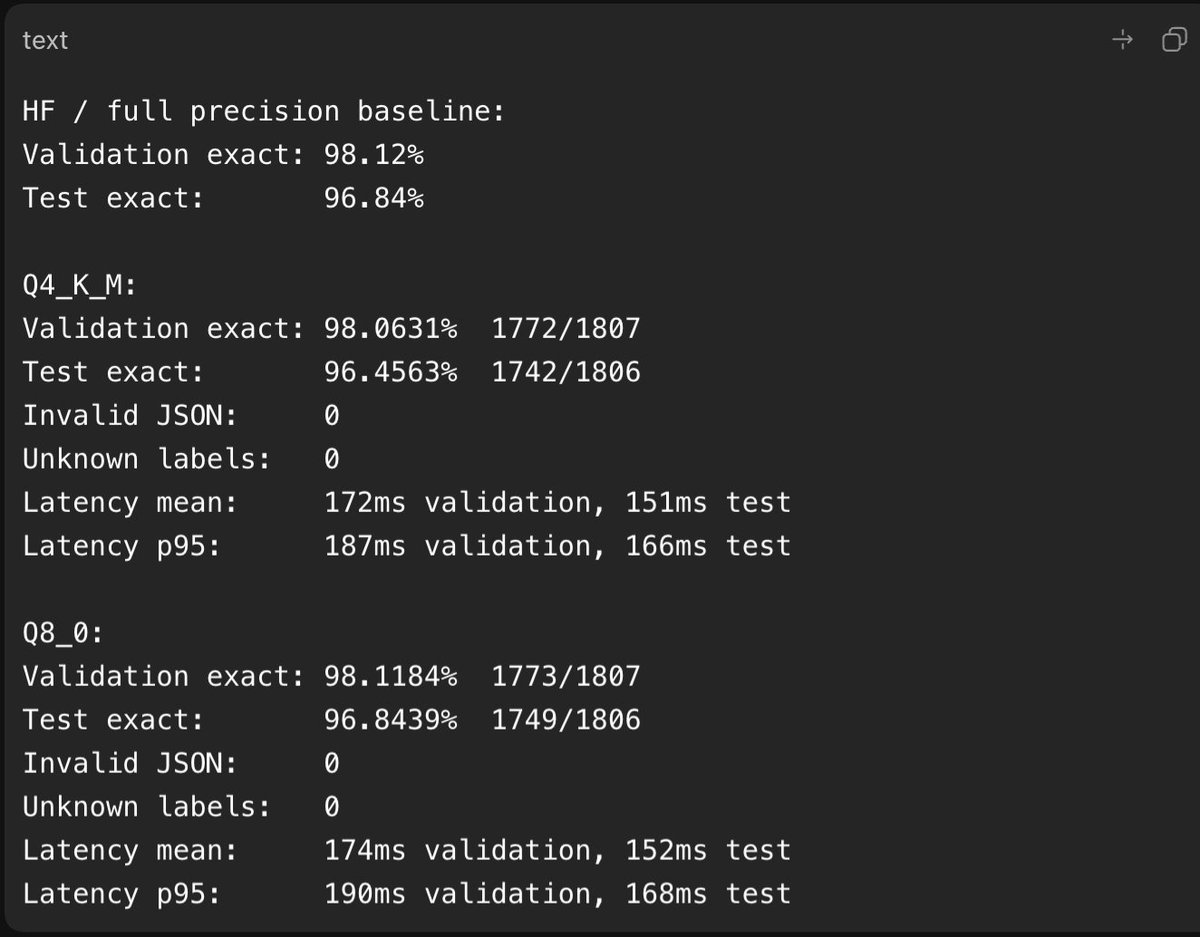
@cjzafir I used unsloth as a test to train the 0.8B Qwen3.5, obviously it's rapid but also quite useful. I used GLM-5 to generate a 4000 training inputs and 250 validation cases from my codebases at work, it generates code based on those even on a CPU at an amazing rate.
English
Joe Gibbons retweetledi

For more details and results check the full blog at vllm.ai/blog/turboquant .
This is joint work with @mgoin_ and Alexandre Marques from @RedHat_AI and @vllm_project .
English