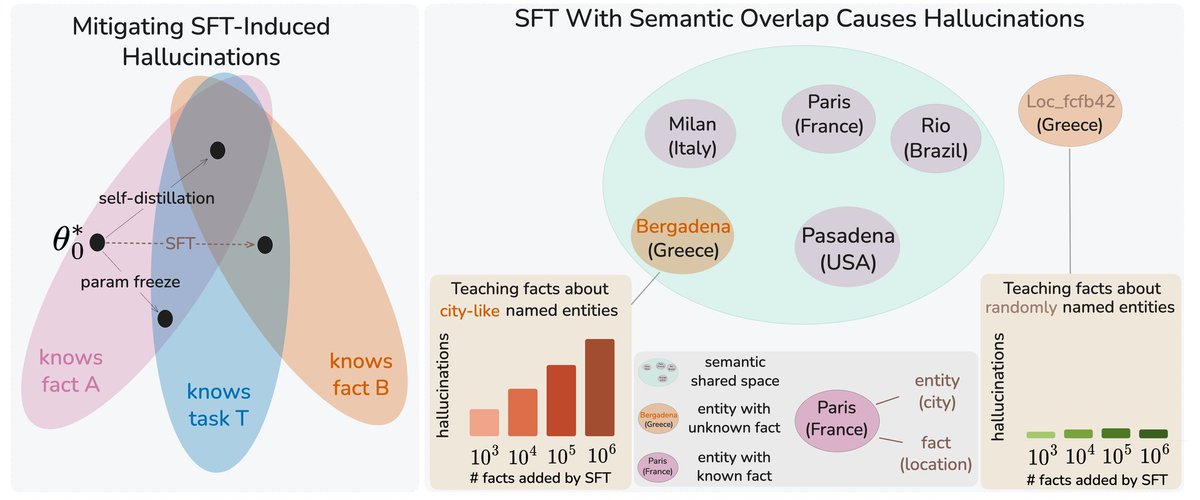
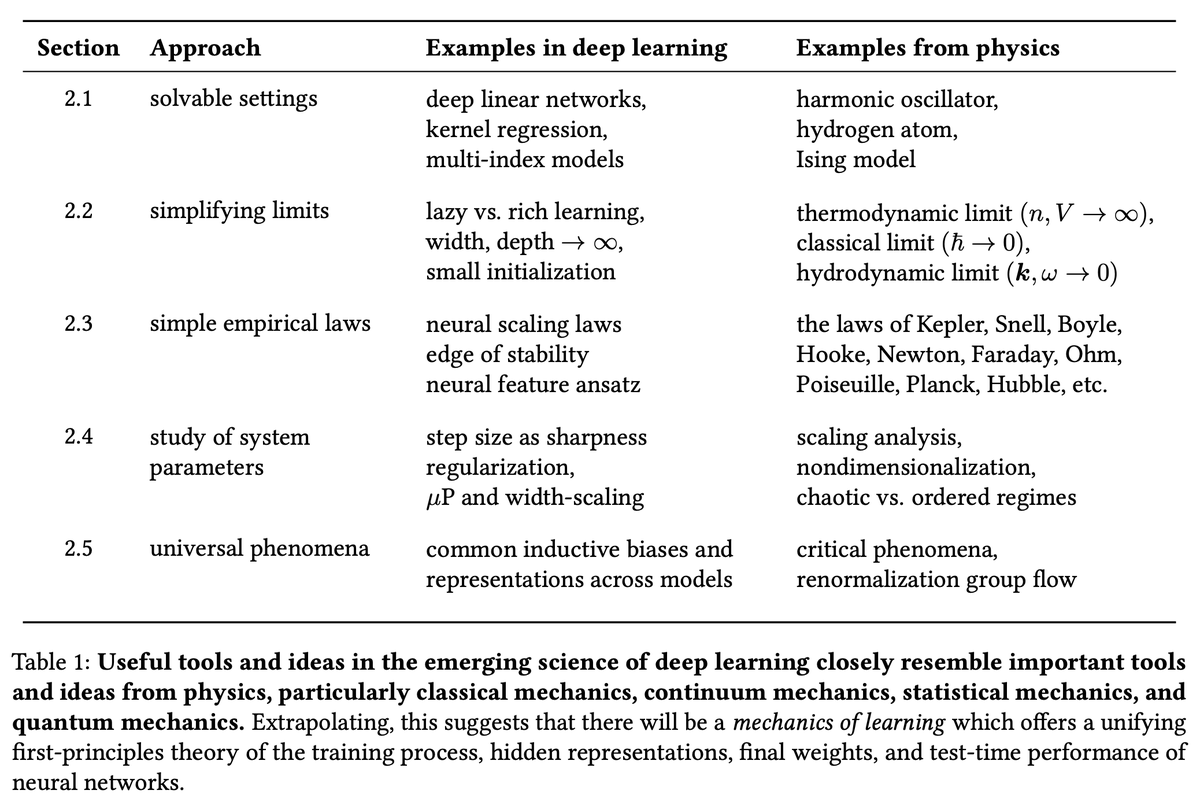
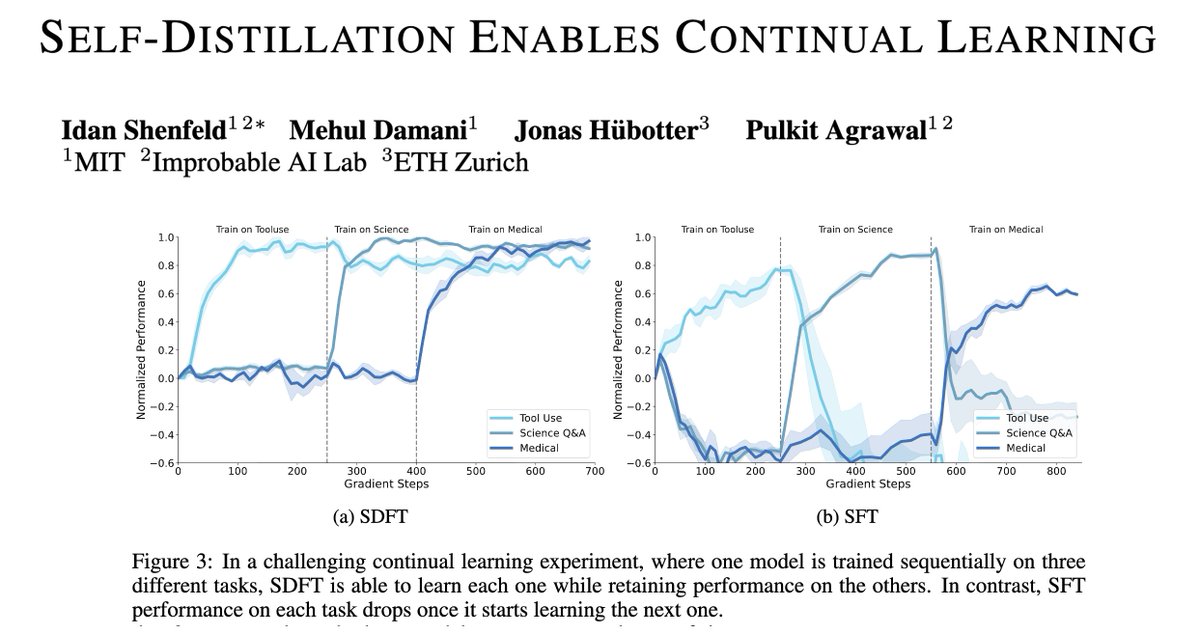
Sabitlenmiş Tweet

📢Curious why your LLM behaves strangely after long SFT or DPO?
We offer a fresh perspective—consider doing a "force analysis" on your model’s behavior.
Check out our #ICLR2025 Oral paper:
Learning Dynamics of LLM Finetuning!
(0/12)

English