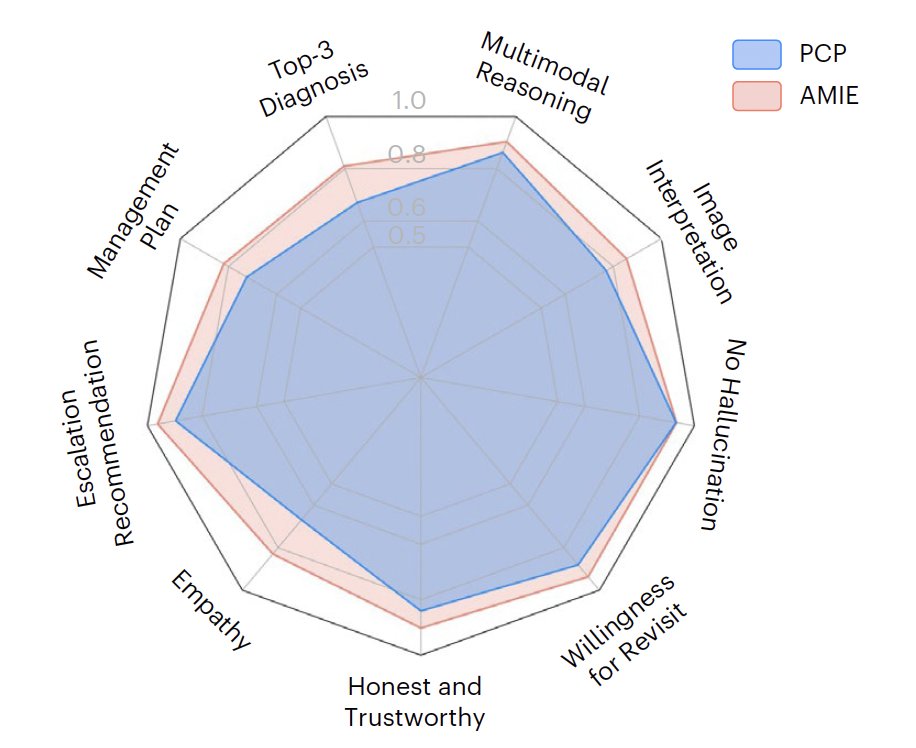
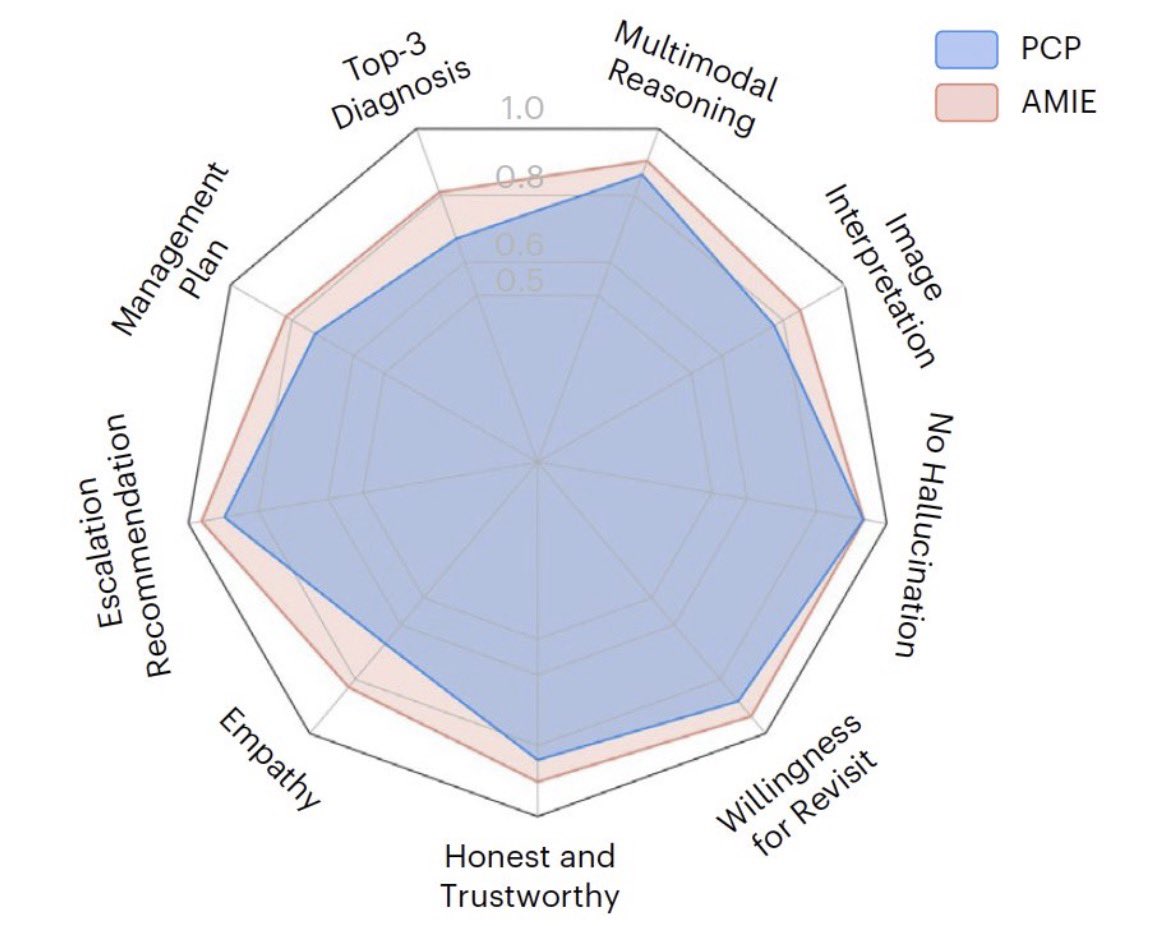
Sabitlenmiş Tweet

Community oncologist. I use AI to appraise clinical trials, then verify every finding against the primary data. The AI gets graded too. One trial, two readers, one bottom line. The Source Report on YouTube (in bio) and Substack.
allenlimd.substack.com
#onced #oncology #meded
English