
Emre Coklar
1.4K posts

Emre Coklar
@EmreCoklar
Senior Consultants, AI Engineer, DSPy enthusiast, Founder. Building: https://t.co/CrtF7NC69g & https://t.co/iS5Ys2Cwdw
Houston, TX Katılım Kasım 2015
91 Takip Edilen269 Takipçiler



Btw, if you provide a skill to users and want to ship a Fable version, check out the pattern in gskill:
Shangyin Tan@ShangyinT
GEPA for skills is here! Introducing gskill, an automated pipeline to learn agent skills with @gepa_ai. With learned skills, we boost Claude Code’s repository task resolution rate to near-perfect levels, while making it 47% faster. Here's how we did it:
English
@andrewmccalip @AmpCode tried this but I don't think the economics worked out
English

Get paid to wait
The Claude Code spinner might be the most watched line on Earth.
So I turned it into an ad marketplace.
Advertisers bid on it. You keep 50% of the money.
Install the extension → get cash from ads.
Introducing Kickbacks
English
@MaximeRivest I feel like "fable talks a bit weird" is an understatement. I have a really hard time digesting it's outputs.
English

So, because of fomo, I have been trying Fable in claude code. I have no loyalty to anthropic and will unsubscribe as soon as competition does its thing but here are my first few hours impressions:
- claude code does not flicker anymore :O
- claude code feels like a cyberpunk giant spaceship compared to Pi.
- fable talks a bit weird. i dont like it.
- claude code remove a lot of the control I have in pi to have different specialized system prompt for different steps in my workflow. this makes me rely more on the model to just 'get it'. Fable does indeed get it a lot more then other models, but its mandatory pairing with claude code makes it immensely wasteful
- fable is very capable of using the full 20x max usage. To early to tell if it produces good stuff. So far. a lot more time/cost to produce less and more reviewable code.
- fable is pretty good at finding surprising things/bugs and reporting them back.
English
English

why is the loops thing breaking everyone's brain?
even three years ago this was conventional wisdom
dan@irl_danB
@Pranav__Goel @emilymbender fwiw I think the entire question "do LLMs [on their own] have agency" kind of gets it wrong, bc its trivial to put an LLM in a while loop with a REPL which effectively grants the system (REPL + LLM) agency even if the LLM itself on its own is not "agentic" (whatever that means)
English

It was a really special day yesterday for me
- 06.06.26
- 6th anniversary with my soulmate
- 10 years together
- our daughter is ~6 month old
- fff is getting more usage than ever
Extremely happy to be on this journey! And excited for much more to come

English


Worst VC behaviour I’ve seen in a portfolio company:
A euro VC limited founder salaries to a very low level (<$100k).
Founders then received a 9 figure acquisition offer.
VC tried to block the deal as was only a 4-5x for them.
I and other angels told them in no uncertain terms that we would go scorched earth on their reputation if they blocked the deal.
The worst part: they failed to connect the fact that their miserly salary cap was likely the cause of the founders wanting to accept the offer.
One of the founders was still renting a 1 bed apartment at this time and had a bunch of credit card debt.
You should want your founders to be financially comfortable post series A so they can really swing for the fences…
Matthew Prince 🌥@eastdakota
Two of our worst VC stories: 1. A Sequoia partner passed on Cloudflare because he didn’t think a woman could lead a security infrastructure company. Seriously. 🙄 2. I got introduced to @pmarca. Meeting got scheduled for a Monday, which should have been a clue. I thought it was just a casual meeting. He thought it was a pitch and brought the whole @a16z partnership team. Hilarity ensued. 🤪 At one point one of them said: “You don’t seem very prepared.” Which was true because I wasn’t. I framed the rejection letter they sent.
English

@rankintweets I can already tell I'll be turned down when the interviewer realizes I drink Coke Zero instead of Diet Coke 😩
English

@MartinShkreli It's not about model, it's about harness. Check out Warden by Sentry x.com/i/status/20492…
David Cramer@zeeg
I have also open sourced the skills we used in Sentry to prove out this latest iteration. github.com/getsentry/ward… Please use it responsibly. If you find something that others have missed, validate it, and send something up to bounty programs. p.s. Mythos is FUD
English

what are the most cybersecurity-friendly models for identifying vulnerabilities right now? mythos isn't accessible, chatgpt cyber still refuses. what's out there that isn't a wimp?
English

This goes without saying, but @lateinteraction deserves an enormous amount of credit for all the projects I have been involved in over the past 18 months. So much so that it is difficult to put into words lest I get choked up.
I'm incredibly excited to continue collaborating on our research projects, and to test them at scale while I am interning @PrimeIntellect
will brown@willccbb
god i'm so excited to have noah on the team. been trying to get him here for almost a year. his record of innovation at the frontier of algorithms + infra for self-improving ai is honestly insane, and i think his recent work is my favorite yet. idk how he's so chill about it.
English

saw @zeeg IRL and he didn't even scream at me. very disappointed.
English

@badlogicgames @GregKamradt @AJKemps @lucasmeijer But but I was promised intelligence too cheap to meter!
English
@GregKamradt @AJKemps @lucasmeijer the expensive part wi hit all coding agents eventually. amp is just ahead of that curve.
English

greg from ARC Prize is daily driving amp!
Greg Kamradt@GregKamradt
How do we compare model perf in ARC-AGI-3? In most benchmarks you just compare scores, but with ARC-AGI-3 you get reasoning logs across all the games you play To compare Opus 4.8 to Opus 4.7 we used LLM as a judge Using @AmpCode (my daily driver right now) I set up a skill to compare models, then it spawned a sub-agent per game per model Each sub agent did a single-game analysis, then brought its notes back to the main agent Very cool to see all of this come together. It would have taken 2-3 days of analysis by hand before
English
@mitsuhiko @fullpatstack I feel like this is a problem your product could evolve to solve.
English

I remember when I enjoyed 1Password. Those days are long gone. And bitwarden is down a dark path. Is there something actually good in that space? If not: why not?
English
Wow, search over 600M vectors in 10ms with 1 CPU. This is huge!
Silvio Martinico@SilvioMartinico
For the final refine phase, we implemented a cache-optimized Product Quantization (PQ) layout specifically tailored for late interaction. Evaluated on ColBERTv2.0 embeddings, it results in 10 ms single-CPU retrieval on large-scale datasets (MS MARCO-v1, LoTTE Pooled).
English
@ibragim_bad @Shevan05 @agolubev13 What I find most interesting is that you found a way to make Gemini 3.1 Pro work when everyone has written it off as useless. I don't know of any other harnesses that are able to make it useful.
English

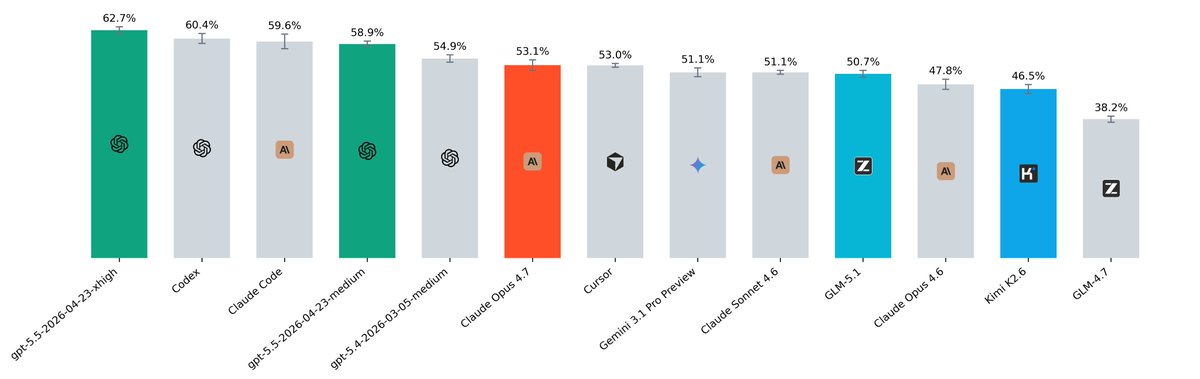
🚨 SWE-rebench big March-May update!
SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub.
updates:
> we collected more fresh and complex tasks
> we ran 110 tasks × 5 for each model / scaffold
> the differences between models and scaffolds are now easier to distinguish
> we will update the task set every two months, with model updates in between
insights:
> GPT-5.5 xhigh takes #1 with 62.7% resolved and 70.0% pass@5
> Cursor with Composer 2.5 is very cheap and strong: around 8× cheaper than Claude Code and Codex, and scores higher than open-weight models! @leerob
Model updates will come in 1–2 weeks. Please send requests for models you want us to run!
🏆 Full leaderboard (check for price / tokens per problem, pass@5, scaffold params, etc):
swe-rebench.com
👾 Join our Discord:
discord.gg/V8FqXQ4CgU
English
RepoPrompt was one of the only tools worth paying for and now it's free! Congratulations to Eric and to OSS!
eric provencher@pvncher
I wrote an extended blog post if you want to read more about all this! repoprompt.com/blog/repo-prom…
English
@fullpatstack Just buy it for me so that you can make fun of me instead. Win win.
English

i kind of want to make fun people paying for this.
i kind of want to buy it too.
this is basically ferrari lucem
jack friks@jackfriks
i made an app that feeds you to the sharks if you don't publicly launch your own product in 30 days. no more of this: "dude i just 100x'ed my workflow with this new AI model"... meanwhile... 0 projects launched 0 revenue 0 users 100 x 0 = still 0. it's time to go from 0 to 1. it's time to: SHlPORDIE.COM 🏴☠️. ship a new product every 30 days until one changes your life or... DIE, in the app, and get kicked from the community forever while being publicly humiliated. no refunds for those who fail to ship. custom trophies to be collected for those who succeed. if you DO ship, you also get to remain in a community of people who actually ship things and get users ++ revenue. sidenote: i'm really excited to see if this can be the push someone needs like how @marclou's shipfast project pushed me and is the entire reason i have a $35K MRR solo operated SaaS now and many other successful mobile apps GLHF, DON'T DIE, and KEEP GOING!! i've never taken a launch this legit so let's see how it goes :)
English