Tri Dao@tri_dao
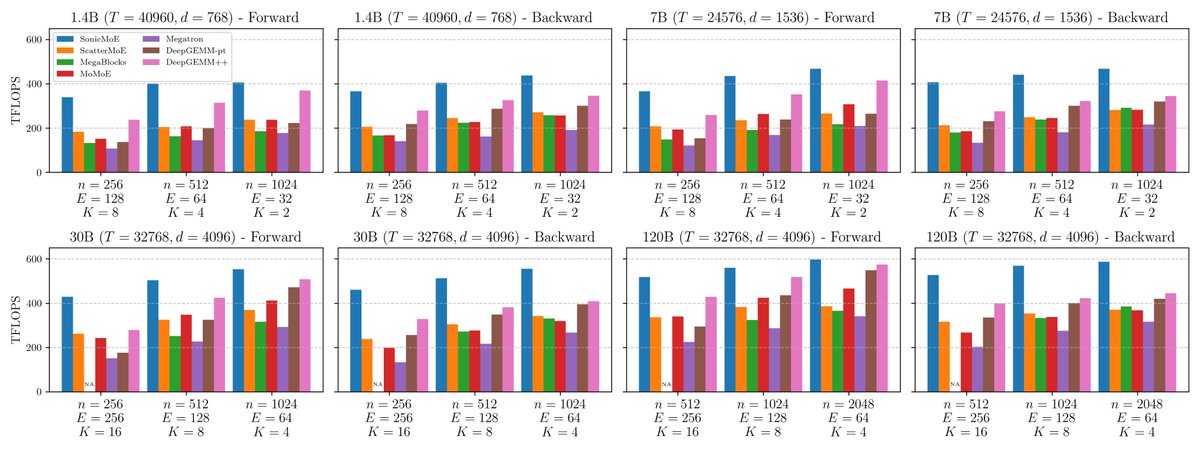
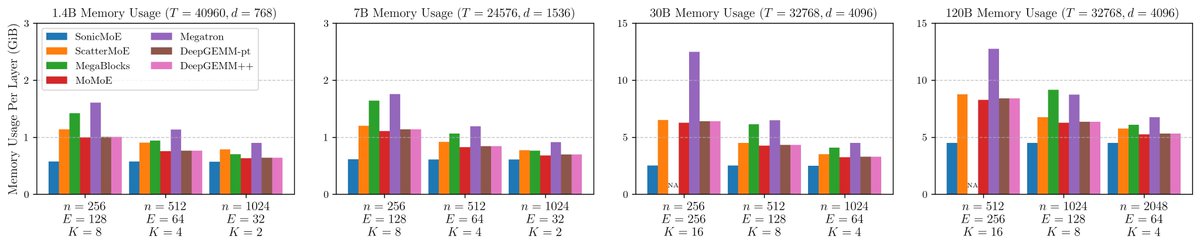
This is what we've been coking for the last 9 months: make MoEs training goes ~2x faster and ~2x less memory! Highlights:
- MoE typically takes the most time and memory in modern models. Turns out one can mathematically rewrite the MoE backward pass to reduce the activation mem you need to store in the fwd by ~2x, resulting in the same gradients with no extra matmul recomputation. I really like this result, as it combines both algorithmic and systems insights.
- Analyzing bottlenecks in MoE layer leads to a natural optimization stragegy: reduce mem reads/writes as much as possible! Gathering the input for fwd and output grad for bwd can sometimes take as much time as the grouped GEMMs. We fuse gather with grouped GEMM + overlap mem access and compute to make the whole layer goes ~2x faster.
- Computing top-k for expert routing can take surprisingly long, ~15-20% of the whole MoE layer! Standard top-k impl uses radix top-k algo, great for large k but suboptimal for small k. We rewrote top-k using bitonic top-k algo, and it's sometimes 20-30x faster than pytorch's top-k!
All the main kernels are written in Cute-DSL so they should be easy to extend (and install :D). Hopper kernels are out, Blackwell kernels are just about ready. MoE models used to be 2x less hardware-efficient to train, hopefully Sonic-MOE will change that.