Sabitlenmiş Tweet

Honored to Be Recognized Among the Top 50 Global Thought Leaders in Agentic AI for 2025 by @thinkers360! linkedin.com/posts/renatosa…
English
Renato Azevedo Sant Anna
984 posts

@renatoaz
Christian, Brazilian, AI Blogger - Digital Business & Insights Consultant | Mentor at FastCapital I can guide your Content Strategy to produce tangible results.


Terrence Tao on AI and math: 5 stages of grief; denial fading Same thing in theoretical physics!








We've redesigned Claude Code on desktop. You can now run multiple Claude sessions side by side from one window, with a new sidebar to manage them all.



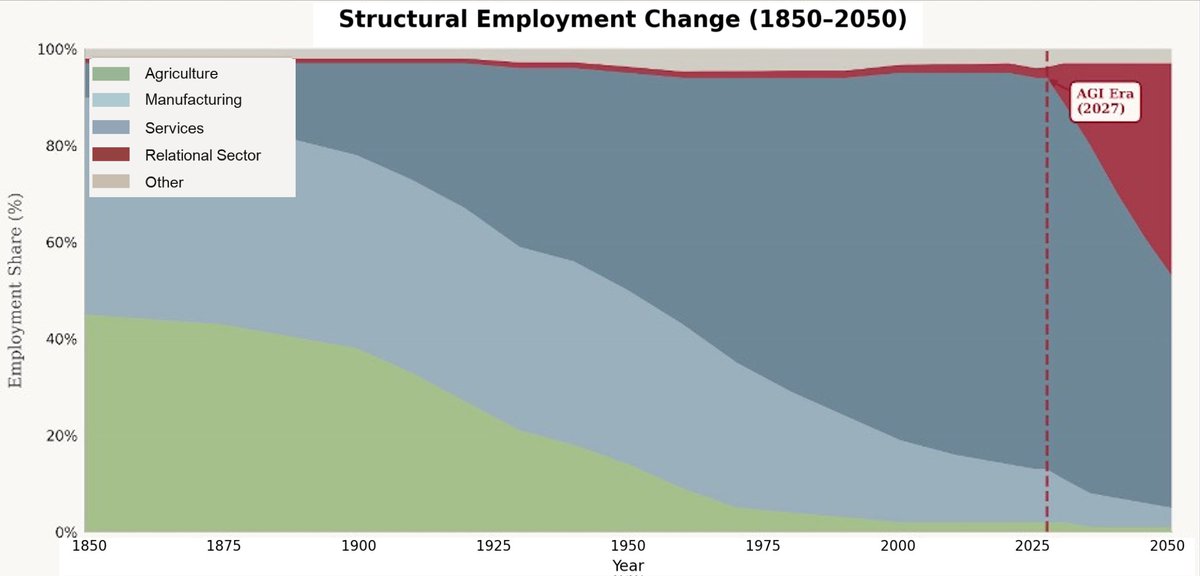








bad news LLMs are hitting a wall